
これは ドリコム Advent Calendar 2020 の22日目です。 21日目は 渡辺 祥二郎 さんによる「【3Dディレクター&アニメーター必見】モーション工数大幅削減でこのプロジェクトを乗り切れ(゚Д゚;)2020」です。
はじめに
ソフトウェア開発において読みやすいコードには価値があります。本稿ではコードの読みやすさについて考察し、特にオブジェクト指向言語で読みやすいコードを書くための一つの手順を説明します。また社内のコードの一部をその手順に沿ってリファクタリングし、読みやすく書き換えても性能が劣化しないことを確かめます。
読みやすいコードの価値
ソフトウェアを開発、運用してサービスを提供するとき、そのコードが読みやすいことには価値があります。コードが読みやすければ拡張しやすく、複数人で開発するのも容易であり、より高度なソフトウェアをより速く開発できます。開発にあたるエンジニアが多いほどコミュニケーションのコストは増えますが、読みやすいコードはコミュニケーションのコストを下げ、トラブルを減らし、効率的な開発の基盤となります。開発が速ければより短時間により多くの施策を試すことができ、ビジネスとしての成功の確率も上がります。読みやすいコードはソフトウェア事業の要となる要素なのです。
読みやすさ
では読みやすさについて分析していきます。読みやすさには主観的な部分と客観的な部分があります。
主観的な読みやすさ
主観的に読みやすいのは、読む人が慣れ親しんだ書き方のコードでしょう。たとえばチーム毎にコーディング規約を決めている場合、自分のチームのコードは読みやすいと感じるでしょう。同じことが他のレベルでも言えます。知らないプログラミング言語で書かれたコードより知っている言語で書かれたものの方が読みやすいでしょうし、言語が採用しているパラダイムが慣れ親しんだものなら読みやすいでしょう。つまり自分が慣れた規律に沿って書かれたコードは読みやすいと感じるはずです。
客観的な読みやすさ
コード量
一方、客観的に読みやすいと言える指標もあります。その一つがコード量です。ここで言うコード量は行数ではなく、コードを構成する要素の種類と数です。たとえば100個の計算を含むコードより1個で済ませるコードの方が速く読めるはずです。
コード量を計る手法の1つがABC Metricで、コードに含まれる代入(Assignment)、関数呼出しなどによる処理の飛躍(Branch)、条件分岐(Conditional)の数から算出します。具体的には代入、飛躍、条件分岐の数をそれぞれ自乗して足し合わせ、平方を取ります。プログラミング言語に依存せず適用できる手法と言えます。
弊社のいくつかのサービスではプログラミング言語にRubyを採用していますが、RubyにはFlogという静的解析ツールもあります。Flogは多くの著名な開発者が所属するSeattle.rbで開発され、そのスコアが高いほど退屈で、苦痛に満ち、テストしにくい(torturous, painful, hard to test)と評価されます。評価方法として動的なProcオブジェクトやclass_evalに強い重み付けをするのが特徴的です。その評価方法から、Flogもコード量を計るツールと言えます。
複雑さ
コード量が同程度でも、複雑なコードは読むのに時間がかかり、読みにくいと言えるでしょう。読みやすいコードは複雑であってはいけません。
ソフトウェアの複雑さを計る指標としては循環的複雑度(Cyclomatic Complexity、以下CCと記す)が挙げられます。CCでは対象の処理が取りうるフローの数をもとに評価します。同じコードでも条件によって実行される処理が異なるとき、その派生が多いほど複雑と捉えます。
Rubyの静的解析ツールのRubocopではPerceived Complexity(以下PCと記す)という指標を計測できます。PCは分岐を引き起こす要素の種類と数を元に評価するのでコード量的な面がありますが、分岐に特化していることとその名前から、ここでは複雑さの計測ツールに分類します。
その他の指標
その他の指標としてRubocopでは以下の項目を計測できることから、指標として一定の支持を得られていることがわかります。
- クラスの長さ
- モジュールの長さ
- メソッドの長さ
- ブロックの長さ
- ネストの深さ
- 引数の数
なおABC MetricとCCもRubocopで計測可能です。
読みやすいコードを書くための選択
読む人を想定する
読みやすいコードを書くには、主観的な読みやすさと客観的な読みやすさを満たす必要があります。上述の通り、主観的な読みやすさを満たすには読む人が慣れている書き方をすれば済みます。よって、読む人が分かっているならその人向けに書けば十分です。しかしそのような状況は限られているでしょう。高度なソフトウェアを継続して速く開発するには複数のエンジニアが安定的に必要で、それを維持するにはメンバーの入れ替わりを想定しなければなりません。企業内の閉じた環境であってもコードを読む人は制限できないのです。もしオープンソースのソフトウェアを開発するのであれば、読む人の数は正に無制限になります。よって特別な状況でなければ読む人の制限は非現実的です。
パラダイムに従う
それぞれのプログラミング言語には前提とするパラダイムがあり、そのパラダイムに沿ってコードを書くための機能を備えています。例えばオブジェクト指向言語であればオブジェクトを一つの単位として生成したり受け渡したりといった操作を表現しやすくなっています。逆に前提としない機能が省かれていることもあり、例えばメモリ上のアドレスを指定できる言語は少なくなりました。
ここで留意すべきは、プログラミング言語が前提としないパラダイムでもコードは書けることです。それぞれのパラダイムに必要な機能群は重なり合い、あるいは包含関係にあるので、必要な機能さえあればプログラミング言語の想定に関わらず任意のパラダイムを採用できます。極端な例としては、すべてのプログラミング言語はチューリングマシンと同等の機能を持つので、言語に関わらずチューリングマシンで実装するといった選択も考えられます。
しかし読みやすいコードを書くならプログラミング言語が前提としているパラダイムを採用すべきです。なぜならそれが読み手が想定している表現であり、主観的な読みやすさを提供すると期待できるからです。
プログラミングパラダイムの中でもオブジェクト指向には約50年の歴史があり、プログラミング言語のシェアとしても優勢なので、本稿ではオブジェクト指向で読みやすいコードについて解説していきます。
オブジェクト指向の品質と原則
オブジェクト指向を表現する資料はさまざまありますが、ここには後述するリファクタリングの基盤としたものを紹介します。
CLEAN
CLEANはDavid Scott Bernsteinが考案した略語で、下の5つの品質の頭文字です。
- Cohesive(凝集)… 各クラスが1つのものを扱うこと。
- Loosely coupled(疎結合)… オブジェクト同士が意図した関係だけを持ち、想定外の影響を与えないこと。
- Encapsulated(カプセル化)… インターフェースと実装が切り離されていること。実装を知らなくても使えること。
- Assertive(断定的)… オブジェクトが扱うデータはそのオブジェクトが持っていること。
- Nonredundant(非冗長)… 想定外の冗長性がないこと。ある一つの意図を表すコードが1箇所にあること。
これらはある一つの性質を別の側面から描写しているに過ぎません。たとえば凝集度の高いオブジェクトは自然と断定的になり、カプセル化が促進され、そのようなオブジェクトの集合はお互いに想定外の影響を与えにくく、冗長にもなりにくいということです。それぞれの品質がお互いを支持する関係になっています。
より詳しい説明は、David Bernsteinの著書『レガシーコードからの脱却』に記されています。
SOLID
SOLIDはRobert C. Martinによって提唱された下の5つの原則を指す略語です。
- Single responsibility principle(単一責任の原則)… Cohesiveと同じ。
- Open-closed principle(開放閉鎖の原則)… オリジナルを変更せずに拡張できること。
- Liskov substitution principle(リスコフの置換原則)… 派生クラスが基底クラスと入れ替わっても動作すること。
- Interface segregation principle(インターフェース分離の原則)… 利用側の種類毎に別のインターフェースを持つこと。
- Dependency Inversion principle(依存性逆転の原則)… 自身より抽象的なクラスに依存すること。
これらはRobert Martinの著書『Agile Software Development, Principles, Patterns, and Practices』(邦訳『アジャイルソフトウェア開発の奥義』)で解説されています。また後に書かれた『Clean Code』にも登場するので、どちらを読んでもより詳しい説明を得られるでしょう。
実践する
ここからは実際に運用されているコードのリファクタリングを例に、オブジェクト指向の原則を実践する手順を紹介します。要点は以下の3つです。
- 出来事と物(人)を分ける
- 大枠から設計して階層化する
- 自然なインターフェースを探す
例に挙げるコード
例に挙げるのは弊社で運営しているゲームの中でユーザー同士の対戦のために相手を選出する処理で、Rubyで書かれており、おおむね次のような流れになっています(機密のため実際の仕様と多少異なります)。
- 自分より上位且つ強いプレイヤーセグメント、同等のセグメント、自分より下位且つ弱いセグメントから1名ずつ選出
- もし自分より高位または低位のセグメントがなければ、単に自分より強いまたは弱いプレイヤーから選出
- もし自分より強いまたは弱いプレイヤーがいなければ、同等のプレイヤーから補完
- もし3名のプレイヤーを選出できなければ、自分と同等のNPC(システムが操作する疑似プレイヤー)から選出
- 以上で3名に満たなければ、最弱NPCで補完
処理の入り口はクラスメソッドで、主な処理は同クラスのクラスメソッド15個と、他のクラスのクラスメソッド1個から構成されていました。インスタンス変数は使われておらず、処理に必要な値は引数として渡しています。
出来事と物(人)を分ける
まず仕様の中からオブジェクトを見つけます。そのとき役立つのが出来事と物(人)の区別です。一部の業界ではコト・モノ・ヒトと呼ぶこともあります。実現したい処理のうちどこまでが出来事で、どこまでが物に属するのか区別し、それぞれを別のオブジェクトに分けます。
たとえばキャラクターが攻撃力と防御力を持っており、その合計で戦闘結果を決めるルールだったとします。勝敗を決めるには合計を求める処理と比較する処理が必要です。この2つの処理がそれぞれ何に属するか意識しなければなりません。この場合、合計を求める処理はキャラクターに、比較は戦闘という出来事に所属させるのがよいでしょう。
もし合計を求める処理を戦闘に所属させれば、他の場所で合計が必要になったとき重複が発生します。これは「非冗長」に反します。一方、比較をキャラクターにさせた場合、そのオブジェクトはキャラクターと戦闘という2つに責任を持つことになり、単一責任の原則に反するからです。
対戦相手の選出の例では、出来事としてMatchingを、物(人)としてUser、PlayerSegments、NpcSegmentsを抽出しました。
大枠から設計して階層化する
仕様をオブジェクトに分解し、それらの関係を分析していくときは、大枠から検討を始め、次第に詳細へと進みます。この順序をアウトサイドインと呼びます。大枠から始めることで関係の弱いオブジェクト同士が初期に分離され、疎結合が促進され、凝集度が高まります。
たとえば上では対戦相手の選出を5つのステップで書きましたが、大枠は「プレイヤーから3名選出し、足りない分をNPCで補完」となります。その分析に沿って書いたコードは下のようになりました(抜粋)。
class Matching
def opponents
matching_players.concat(matching_npcs(count: 3 - matching_players.size))
end
end
opponentsは選出を実行するメソッドであり、performやexecuteという名前でも良い位置づけですが、戻り値が分かりやすいようにopponentsとしました。
階層化
階層化とは、出来事や物を抽象度によって分けることです。上述の通り、階層は外側(抽象側)から分析、設計します。階層でクラスを分解することで、単一責任の原則を維持しやすくなります。
出来事を階層化すると一番外側はあらすじになり、中へ行くに従って詳細な時系列が現れます。一般的な本が章立てされており、章が節に分かれているのに似ています。あらすじを表すクラスをシナリオクラスと呼ぶこともあります。
物を階層化すると一番外側は複数の部品を組み合わせた構造物のようになります。部品はさらに小さな部品から構成されることもあります。このように複数のオブジェクトを組み合わせて抽象的なオブジェクトを構成することをコンポジションと呼びます。
対戦相手の選出の例では、上に示したopponentsから下のような階層を作りました。
matching_players… プレイヤーから最大3人の対戦相手を選ぶmatching_player1… 強いプレイヤーを優先して1人選ぶplayer_segments.upper_strongers… 上位で強いプレイヤーセグメントplayer_segments.even_strongers… 同順位帯で強いプレイヤーセグメントplayer_segments.upper_competings… 上位で同等のプレイヤーセグメント
matching_player2… 同等のプレイヤーから1人選ぶplayer_segments.even_competings… 同順位帯で同等のプレイヤーセグメントplayer_segments.even_strongers… 同順位帯で強いプレイヤーセグメント
matching_player3… 弱いプレイヤーを優先して1人選ぶplayer_segments.lower_competings… 下位で同等のプレイヤーセグメントplayer_segments.even_weakers… 同順位帯で弱いプレイヤーセグメント
matching_npcs… NPCから指定された数の対戦相手を選ぶnpc_segments.competings… 同等のNPCセグメントnpc_segments.weakests… 最弱のNPCセグメント
なお、同一クラスの中でも階層が見つかればメソッドを分けておきます。そうすればメソッドの長さと複雑さが下がって読みやすくなりますし、そのクラスを分解する必要が生じたときメソッドを移動するだけで済むことが多く、改修が簡単になるからです。例えば上述のopponentsとmatching_playersは同じMatchingクラスに所属しています。
自然なインターフェースを探す
出来事を表すクラスはより詳細な時系列を表すクラスにメッセージを送り(メソッドを呼び)処理を進めます。また物を表すクラスは製品としての情報を組み立てるために部品にメッセージを送ります。このようなインタラクションの妥当性を「自然さ」で評価しながら決めていきます。自然さはメッセージの受け手が担っている責任とメッセージの整合性とも言えます。受け手が持っているデータ、担っている責任に関するメッセージは自然で、そうでないものは不自然です。
またメッセージは「どのように」を避けて「何を」を表すように決めます。たとえば戦闘力を返すメッセージは「combat_point」などになり、実際の処理が攻撃力と防御力の加算であっても「add_attack_and_defense」とはしません。なぜなら実際の処理は受け手のオブジェクトの責任であり、それが外に漏れたら「カプセル化」に反するからです。
設計を確かめるときにはシーケンス図が役に立ちます。シーケンス図ではオブジェクトを横に並べ、それぞれから1本の根のように下へ線を引きます。そしてメッセージを送るオブジェクトの「根」から受け取るオブジェクトの「根」へ向かって横に矢印を引き、メッセージを表現します。上から時系列にメッセージを並べることで、一連の処理に関わるメッセージを俯瞰できます。
例えば対戦相手選出は下図のようになります。
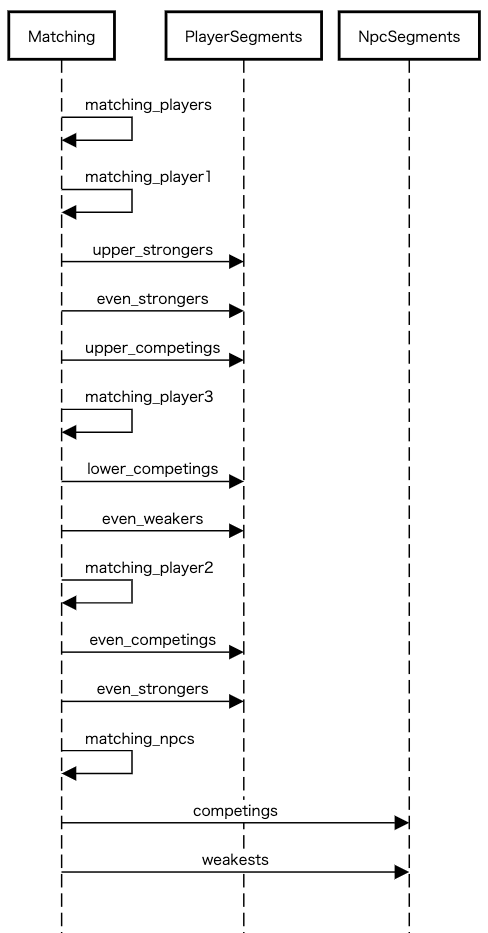
以上のように実現したいことからオブジェクトを抽出し、インターフェースを探すことで全体の設計が決まります。
リファクタリングされたコード
上述の方法で対戦相手選出処理を設計、リファクタリングした結果、コードの本体は5個のクラスと43個のインスタンスメソッドになりました。(オリジナルとの互換性を維持するため、処理の開始地点となるクラスメソッドは残してあります。)
静的解析結果
リファクタリング前後で静的解析結果は下表のように変化しました。Rubocopではすべての項目の許容範囲を0に設定する(何も許容しない)ことで全計測対象の値を表示させました。
| 計測方法 | 前 | 後 |
|---|---|---|
| ABC Metric 合計 | 225.52 | 266.65 |
| ABC Metric メソッド平均 | 14.09 | 6.20 |
| Flog 合計 | 334.6 | 369.3 |
| Flog メソッド平均 | 19.7 | 7.7 |
| CC メソッド平均 | 3.13 | 1.79 |
| PC メソッド平均 | 3.25 | 1.86 |
| クラスの長さ 合計 | – | 165 |
| クラスの長さ 平均 | – | 33.0 |
| モジュールの長さ 合計 | 176 | 18 |
| モジュールの長さ 平均 | 176 | 18 |
| メソッドの長さ 合計 | 139 | 82 |
| メソッドの長さ 平均 | 8.69 | 1.91 |
| ブロックの長さ 合計 | 20 | 17 |
| ブロックの長さ 平均 | 2.22 | 2.13 |
| ネストの深さ 平均 | 1 | 1 |
| 引数の数 平均 | 2.38 | 1.3 |
コード量の合計はリファクタリング後の方が大きくなりました。ABC Metricで約18%、Flogで約10%の増加です。これはオリジナルのコードがローカル変数を参照する場面でリファクタリング後のコードはメソッドを呼ぶ箇所が多いことが一つの要因です。前述の通り、ローカル変数の参照はコードサイズに算入されませんがメソッド呼び出しはされます。ただしコード量のメソッド平均は大幅に下がり、ABC Metricでは約56%、Flogでは約61%の減少です。
クラス/モジュール/メソッドの長さの関係を見ると、元のコードにはクラスがなかった(コード全体がクラスメソッドを追加するモジュールだった)ので値がなく、モジュール長が176でした。リファクタリング後はクラス長165とモジュール長18の合計183で、約4%増加しています。ところがメソッド長の合計は元の139から82へと約41%減少しています。これはメソッドを宣言するdef my_methodのような行がクラス/モジュール長としては計測対象になり、メソッド長としては対象にならないためだと思われます。
複雑さの変化を見ると、CCでは3.13から1.79へ約43%の減少、PCでも3.25から1.86へ約43%の減少になっています。これはメソッド平均ですので、全体の複雑さが同じならメソッド数を増やせば下がるのは当然です。多数の単純なメソッドへの分解はオブジェクト指向でなくてもできるので、直接の影響とは言えませんが、出来事と物を分けたり、階層化したりといった方向性が貢献した部分はあるでしょう。
コードは公開できないので、参考としてエディタのミニマップのスクリーンショットを添付します。
静的解析結果から言えるのは、リファクタリングによって全体のコード量は若干増え、個々のメソッドの読みやすさは大幅に改善したということです。この変化はコードの一部を修正したり拡張したりするときにメリットがあるでしょう。
性能の変化
コードが読みやすくなるとしても、性能が悪化したら許容されない場合もあるでしょう。
例に挙げた処理には様々なケースのテストコードがありましたので、選出処理の前後で時刻を取得して処理時間を計測しました。各ケースを10回ずつ実行し、平均をとりました。また全ケースを実行する間に発行されるDBクエリの回数と、合計処理時間も計測しました。DBアクセスにはActiveRecordを使っており、クエリ処理時間がログに出力されますので、それを採用します。なおテスト用データを作成するときのクエリ(INSERT)は除去しました。結果を下表に示します。
| 計測内容 | 前 | 後 |
|---|---|---|
| 選出処理時間 平均(ミリ秒) | 215.0 | 211.4 |
| 選出処理時間 中央値(ミリ秒) | 167.2 | 165.8 |
| DBクエリ合計処理時間 平均 (ミリ秒) | 62.4 | 62.2 |
| DBクエリ合計処理時間 中央値 (ミリ秒) | 57.8 | 62.2 |
| DBクエリ回数 | 124 | 121 |
全体の処理時間とDBクエリ処理時間はそれぞれ約2%、約0.3%の短縮で、ほぼ差がありませんでした。ただしクエリの回数は3回減少していました。原因としては、おそらくDBから読み出した後に変数として保持していない値が元のコードにはあるのだと思われます。このようなケースは値をオブジェクトに管理させることで防ぎやすくなります。つまり必要な値はオブジェクトに問い合わせ、DBからの読み出しは必要に応じてオブジェクトが行うという形です。
結論として、今回のケースではリファクタリングによって性能の悪化はありませんでした。当然ながら元のコードの最適化の度合いによって結果は変わるところですが、コードレビューを通過し市場にリリースされているコードですので、一定の質は担保されています。参考にしてください。
まとめ
読みやすいコードはソフトウェアを中心とする事業を支えます。本稿ではオブジェクト指向で読みやすいコードを書くための価値観と手順の一例を説明しました。またその手順に従って実際に運用されているコードをリファクタリングし、性能に悪影響がないことを確認しました。参考になれば幸いです。
明日は田島雪乃さんのイラストです。
ドリコムでは一緒に働くメンバーを募集しています!募集一覧はコチラを御覧ください!