はじめに
弊社の主な事業はスマホ向けゲームの開発と運営で、DBもゲーム向けのものに関心があります。AWS(Amazon Web Services)とGCP(Google Cloud Platform)でソリューションを検索すると、それぞれDynamoDBとCloud Spannerをゲーム向けと位置づけています。DBの選定はパフォーマンス以外の要因で決まることが多いのですが、純粋なパフォーマンスも知っておきたく、調べてみることにしました。(追記:GCPのサービスのベンチマークを公開する場合は、Googleから書面による同意をもらうなどの要件があります。AWSの方は、再現に必要なすべての条件を公開していれば済みます。)
なお本稿はサーバーエンジニアを対象とした内容になっています。
アクセスの種類
スマホ向けゲームはDBアクセスにおいて一般に書込みの割合が多いアプリケーションであり、同時にチートを防ぐために整合性に厳密な必要があります。数人しかつかわない社内ツールのように「この書込み中にあの書込みは発生しないはず…」といった想定はできません。よって書込トランザクションの計測は必須です。
一方DynamoDBの公式ドキュメントには「書込みが全てのレプリカに伝わる時間は普通1秒以内」という記述があり、実際はどのくらいの時間なのかという声もあったので、整合性のある読出しも計測対象にします。
またついでなので単純読出しも計測します。
計測ツール
DBのパフォーマンス計測ツールとしてYCSBが広く使われていますが、以下のような欠点があります:
- 経過時間によるパフォーマンスの変化がわからない
- レスポンス時間の中央値がわからない
YCSBはオープンソースなので上の欠点を補うように改造もできますが、今回は個人的な理由でGoプログラミングの練習をしたかったので、独自ツールを開発することにしました。詳しくは後述します。
測定条件
2つのサービスで計測するので、条件を揃えた方が結果の価値が高まると考え、できるだけ条件を合わせる方針にします。
リージョン
DynamoDBもCloud Spannerも世界の複数の地域にレプリカを置く設定が可能ですが、今回は弊社プロダクトの要件に合わせてシングルリージョンとします。DynamoDBは東京リージョンを使いますが、Cloud Spannerの方は東京リージョンに計測に使いたい高性能なCompute Engineがなかったので、台湾リージョンを使います。
プロビジョニング
サービス間で条件を合わせるため、費用が同じくらいになるようにセットアップします。DynamoDBの方が細かく性能/費用を調整できるので、Cloud Spannerの構成を先に決め、その費用に合わせてDynamoDBをプロビジョニングします。
Cloud Spannerの性能と費用は主にノードの数で決まります。1ノードでも運用できますが、本番運用では2ノード以上が想定されるので、検証も2ノードで実施します(追記:情報収集したところ、1ノードと2ノード以上で性能以外の差はなく、1ノードでも十分本番運用可能なことがわかりました)。1年分前払いの場合、その費用は月当たり1,366.56ドルになります(実際に運用するときはストレージ費用が別途必要です)。
DynamoDBは読出しと書込みの性能を別々にプロビジョニングできるので、合計金額が1,366.56ドルに近くなるよう設定します。書込トランザクションの試験では全ての費用を書込性能に振り分けます。性能の単位はCapacity Unitと呼ばれ、特に書込性能をWCU、読出性能をRCUと略します。費用は100 WCU/RCU単位で計算されるので、まず最小の100WCUの費用を計算すると、月当たり25.02ドルになります(なお見積もり計算機に従って一月を730時間と考えます)。よってCloud Spannerと同様の費用をかけるなら、1366.56 / 25.02 ≒ 54.61 より、5,400WCU使えることになります。
整合性のある読出しの試験では、まずトランザクションでデータを更新し、直後に整合性のある読出リクエストを発行してレスポンスタイムを測ります。1回の試行にかかるCapacity Unitは、最初の書込みに2WCU、続く読出しに1RCUなので、この割合で予算を振り分けます。書込みの最小費用が上述の通り25.02ドルで、同様に読出しの最小費用を計算すると4.97ドルです。よって整合性のある読出し試験の最小費用は 25.02 * 2 + 4.97 = 55.01 であり、Cloud Spannerと同じ予算をかける場合、1366.56 / 55.01 ≒ 24.84 より、4,800WCU + 2,400RCUとなります。
単純読出しにかけられる費用は 1366.56 / 4.97 ≒ 274.96 より27,400RCU分とします。
データ
ある時間帯に10万人のユーザがゲームをプレイしている状況を想定します。またそれぞれのユーザに「所持金」と「チケット数」というデータがあることにします。
DynamoDBではテーブルが1つで、PK(Partition Key)とSK(Sort Key)としてデータの種類と通し番号を繋げた文字列を使います(下表を参照)。今回の測定にSKは不要ですが、より実在の例に近づけるために組み込みます。所持金は「Gold」フィールドとして「User<ID>」をキーとしたitemに、チケット数は「NumTickets」として「UserItem<ID>」をキーとしたitemに保存します。
| PK | SK | Attribute 1 |
|---|---|---|
| User<n> | User<n> | Gold: <amount> |
| UserItem<n> | UserItem<n> | NumTickets: <num> |
1ユーザ当たり2レコード、合計20万レコードを予め投入しておきます。所持金の初期値は10,000、チケット数は0とします。
Cloud SpannerではUsersおよびUserItemsの2つのテーブルを設け、UsersテーブルにはIdとGold、UserItemsテーブルにはIdとAmountカラムを作ります(下表)。
Users
| Id | Gold |
|---|---|
| <n> | <amount> |
UserItems
| Id | Amount |
|---|---|
| <n> | <amount> |
こちらもそれぞれのテーブルに10万レコードずつ投入しておきます。ただしnは32ビットのビット列に変換し、ビット順を反転して10進数に戻した値とします。例えば1は2147483648に、2は1073741824になります。Cloud Spannerでは複数のノードにデータを分散して保存するために、このようにキーを分散させる必要があります。
アクセス内容
書込トランザクションの試験では、ユーザをランダムに選択し、所持金を5減らしてチケット数を1増やします。ただし本番で想定される状況に近づけるため、ユーザの選択には偏りをもたせます。ユーザのIDは1から100,000までですが、この値を生成するとき0〜50,000の乱数と1〜50,000の乱数を加えます。すると50,000前後のIDが最も出やすくなり、1や100,000に近づくほど選択される可能性が下がります。
整合性のある読出しの試験では、前述の通りトランザクションでデータを更新してから読み出します。具体的には所持金を5ずつ増やすことにします。ユーザの偏りは書込トランザクションと同様です。
単純読出しではUserレコードを読むことにします。
アクセス数
実際の運用ではユーザのアクセスに十分耐えられるようにプロビジョニングするはずです。よって今回の実験でもDBの使用率が飽和するような状況は避け、最大90%ぐらいの使用率になるよう調整します。Cloud Spannerは1ノードでどのくらいのアクセスに耐えられるか事前にわかりませんが(追記:公式ドキュメントにベストプラクティスに従えば1ノード当たり毎秒10,000読出しまたは2,000書込みが可能という記述がありました)、幸いDynamoDBはアクセス規模をCapacity Unitで指定してセットアップできますので、こちらを基準にアクセス数を決めます。
書込トランザクションの試験では1回の試行で2つのレコードをトランザクションで更新するため、4WCUを消費します。プロビジョニングするのは5,400WCUなので、5400 / 4 = 1350 より毎秒1,350リクエストで使用率が100%となります。90%に調整するため、書込トランザクション試験のアクセス数は 1350 * 0.9 = 1215 より1,215リクエスト毎秒とします。
整合性のある読出しでは毎秒2,400リクエストで100%なので実験では2,160リクエスト毎秒とします。
単純読出しは1回の試行で0.5RCUしか消費しないため、27400 / 0.5 = 54800 より54,800リクエストが上限です。よって実験のアクセス数は49,320リクエスト毎秒とします。
実験は1種類につき3分程度で十分だと思われますが、Cloud Spannerには読出頻度データ量や負荷に合わせてデータを分割、再配置する機能があり、その発動にかかる時間が数分とのことなので、単純読出しの試験は10分とします。(追記:データの再配置が複数回発生する可能性があるので、一般的には1時間ぐらいの準備時間をとることが多いようです。また現状の分割数を調べる方法もあります。詳しくはツールを使った Cloud Spanner のウォームアップを参照してください。)
Cloud Spannerのレスポンスタイムは予測不能ですが、DynamoDBは確実に毎秒全てのリクエストに応答するはずです。1秒以内に予定されたリクエストが消化された場合、1秒経過するまで次のリクエストを留め置くことにします。
計測ツール
前述の通り今回はGoプログラミングの練習を兼ねて計測ツールを自作しました。計測だけでなくデータの投入も実装されていますが、テーブル名やカラム名は今回の実験の内容に合わせてハードコーディングされています。ソースコードはGitHubで公開中です(追記:Cloud Spannerのコードはプリペアドステートメントの利用でさらに速くなるとのことで、プルリクエストをいただいて改修しました。また単純読出しでは(*Client)Singleを使った方が処理速度が期待できるとの情報もいただきました)。
以下のようなパラメータをコマンドラインで指定可能になっています。
- サービス(DynamoDB/Cloud Spanner)
- 処理(パフォーマンス測定/データ投入)
- DynamoDBのエンドポイント(URL。localhostも指定可能)
- Cloud SpannerのDB ID
- アクセス種別(書込トランザクション/整合性のある読出し/単純読出し)
- 試験時間(秒)
- 毎秒のリクエスト数
- ローダーの数
- レポート出力間隔(秒)
計測を選んだ場合、「ローダーの数」で指定した数のgoroutine(並行処理のコンテキスト)が作られ、その秒間のリクエストを投げ終わるまで分担して処理します。レポート出力間隔で指定した秒数が経過すると各goroutineがそれぞれ担当したリクエストのレスポンスタイム等を集計して出力します。例えばレポート出力間隔が1秒でローダーが2個なら、毎秒2行のレポートが生成されます。1回のレポートで出力される値は下の通りです。
- 計測開始または前回のレポートから処理したリクエスト数
- エラー数
- レスポンスタイムの平均
- 中央値
- 95パーセンタイル
- 99パーセンタイル
- 最悪値
- 秒間に処理しきれなかった(残っている)リクエスト数
エラーレスポンスの数は数えていますが、特例として複数のgoroutineが同一ユーザの更新をしようとして発生するトランザクションエラーは除外しています。この実験では更新は重要ではなく、レスポンスが明確であれば十分なので、更新の競合は無視しました。
並行数
今回の計測で規定するのは秒間の処理数で、十分処理できる想定で負荷を設定しているので、並行数には特に強い要求はありません。処理が直列になり過ぎて秒間から溢れるのだけ防げばよいでしょう。
書込トランザクションは毎秒1,215リクエストなので、100並行にすると1 gorutine当たり約12リクエストを担当することになります。よって平均約80ミリ秒以下でレスポンスが返ってくれば溢れません。計測ツールは溢れたリクエスト数を表示するように作るので、実際に実行して溢れたリクエスト数を見ながら調整します。
同様に整合性のある読出しも100並行、単純読出しは500並行で実験します。
計測用ホスト
計測ツールを動かすホストとして、DBと同じリージョンに十分なスペックの仮想マシンを確保します。DynamoDBに対してはEC2のc6i.32xlarge、Cloud Spannerに対してはCompute Engineのc2d-highcpu-112を使います。それぞれの大まかなスペックは下表の通りです。
| EC2 (c6i.32xlarge) | CE (c2d-highcpu-112) | |
|---|---|---|
| vCPUs | 128 | 112 |
| メモリ(GB) | 256 | 224 |
| ネットワーク帯域幅(Gbps) | 50 | 32 |
vCPUの数が100個程度なので、500並行で動かすと1 vCPU当たり約5 goroutineを動かすことになりますが、CPU側の処理は十分に軽いので、ほとんどの時間がDBからの応答を待つことになるはずです。実際にどのような振る舞いになるか、監視サービスや計測ツールの出力で確認します。
ネットワークについてはCompute Engineの方が帯域幅が狭く32Gbpsですが、毎秒49,320リクエストでも1リクエスト当たり約80KB使えます。データの項で示した通り、アプリケーションのペイロードは数バイトなので、リクエスト全体でも十分に収まるでしょう。こちらも監視サービスで確認します。
計測結果
DynamoDB 書込トランザクション
書込トランザクションの計測条件は下の通りでした。
| パラメータ | 値 |
|---|---|
| レポート出力間隔 | 10秒 |
| ローダー数 | 100 |
| 試験時間 | 3分 |
| 毎秒のリクエスト数 | 1215 |
つまり3分間にわたり10秒ごとにレポートが出力されるので18回で終わりそうに思えますが、ローダーの起動に数秒かかるので、全体の実行時間が3分4秒で19回のレポートになりました。
よって出力される行数は 19 * 100 = 1900 より1900行でした。結果のスプレッドシートを公開します。
この結果をグラフ化するために、同タイミングの100のレポートをまとめて1つの値にしました。例えば開始10秒目の100個の中央値を平均して1つの点にプロットする、というような操作です。平均値、中央値、95パーセンタイル、99パーセンタイルは平均してまとめ、最悪値は最大値(最悪値の最悪値)を採りました。
以上のように作成したグラフが下の図.1になります。
結果として、平均と中央値は20msec台、95パーセンタイルは30msec台に集中しました。99パーセンタイルは概ね40msec台ですが、1分40秒の時点で一時的に悪化しています。最悪値は変動があり、最大は600msec台でした。全体としては安定した結果と言えそうです。
DynamoDB 整合性のある読出し
計測条件は下の通りでした。
| パラメータ | 値 |
|---|---|
| レポート出力間隔 | 10秒 |
| ローダー数 | 100 |
| 試験時間 | 3分 |
| 毎秒のリクエスト数 | 2160 |
グラフを図2に示します。
図2. DynamoDB 整合性のある読出し
結果としては、平均と中央値が30msec前後、95パーセンタイルが40msec前後、99パーセンタイルは100msec以内、最悪値は500msec台でした。
DynamoDB 単純読出し
単純読出しについても同様に計測条件と結果を下にまとめます。
| パラメータ | 値 |
|---|---|
| レポート出力間隔 | 10秒 |
| ローダー数 | 500 |
| 試験時間 | 10分 |
| 毎秒のリクエスト数 | 49,320 |
図3. DynamoDB 単純読出し
DynamoDB 計測中の負荷
単純読出し計測中のローダーのCPU使用率とネットワーク受信量は図4の通りで、CPU使用率が約16%、ネットワーク受信量は15Gバイト/分=約2Gbpsでした。ネットワーク容量が50Gbpsですので、ボトルネックにはなっていなかったことがわかります。
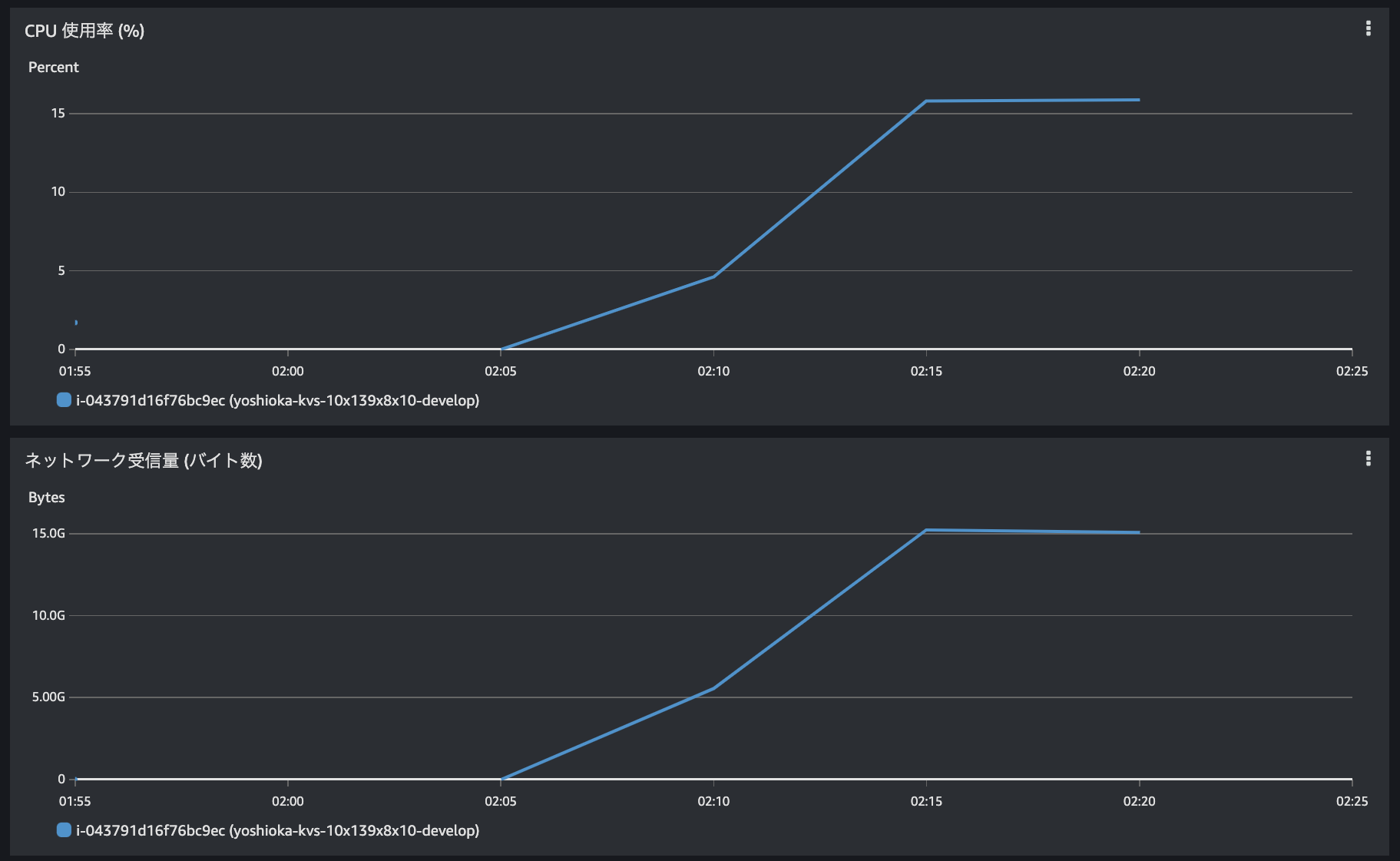 図4. DynamoDB 単純読出し計測中の負荷
図4. DynamoDB 単純読出し計測中の負荷
Cloud Spanner 単純読出し
前述の通りCloud Spannerには読出頻度に従ってノード間でデータを再配置する機能があるので、先に単純読出しを実行して最適化してもらいます。
Cloud Spannerも毎秒49,320リクエストで計測を開始しましたが、最初のレポート出力のタイミング、つまり開始から10秒の時点で未処理のリクエスト数が毎秒のリクエスト数を超えたため、計測ツールが停止しました。つまり月1,300ドルくらいの予算で単純な読出し専用の設定をした場合、Cloud SpannerはDynamoDBほどの性能が出ないことになりますが、ではどのくらいの性能が上限なのか、リクエスト数を下げて試してみました。
すると最初の5分の1である9,864リクエスト毎秒まで下げた時点で10分間の計測ができるようになりました(追記:最初のアクセス時はサービス内部のコンポーネント同士の接続確立などで処理時間が長くなる傾向があるため、徐々にアクセス数を上げていくなどの対処をするとより高いスループットを得られるようです。また前述の通りツールにも改善の余地があったようです)。ローダー数は100にしましたが、毎秒のリクエスト数が同一でもローダー数を200にすると処理できないリクエストが残ってツールが停止しました。最後まで動作した計測条件を下に示します。
| パラメータ | 値 |
|---|---|
| レポート出力間隔 | 10秒 |
| ローダー数 | 100 |
| 試験時間 | 10分 |
| 毎秒のリクエスト数 | 9864 |
グラフを図5に示します。
図5. Cloud Spanner 単純読出し
結果を要約すると、平均と中央値はおおむね8msec以下、95、99パーセンタイルは10msec台、最悪値は400msec台でした。
Cloud Spanner 書込トランザクション
書込トランザクションについては問題なくDynamoDBと同じ1,215リクエスト毎秒を処理できたので、逆にどこまでリクエストを増やせるか試したところ、2,160は処理できましたが、2,295は停止しました。計測条件とグラフは下の通りです。
| パラメータ | 値 |
|---|---|
| レポート出力間隔 | 10秒 |
| ローダー数 | 100 |
| 試験時間 | 3分 |
| 毎秒のリクエスト数 | 2160 |
図6. Cloud Spanner 書込みトランザクション
Cloud Spanner 整合性のある読出し
整合性のある読出しは処理できるリクエスト数がDynamoDBの半分の1,080でした。計測条件とグラフを示します。
| パラメータ | 値 |
|---|---|
| レポート出力間隔 | 10秒 |
| ローダー数 | 100 |
| 試験時間 | 3分 |
| 毎秒のリクエスト数 | 1080 |
図7. Cloud Spanner 整合性のある読出し
Cloud Spanner 計測中の負荷
Cloud Spannerの計測中の負荷は図8の通りで、CPU使用率は7%未満、ネットワークトラフィックは最大で約3MB/sですから、ボトルネックになっていなかったことがわかります。
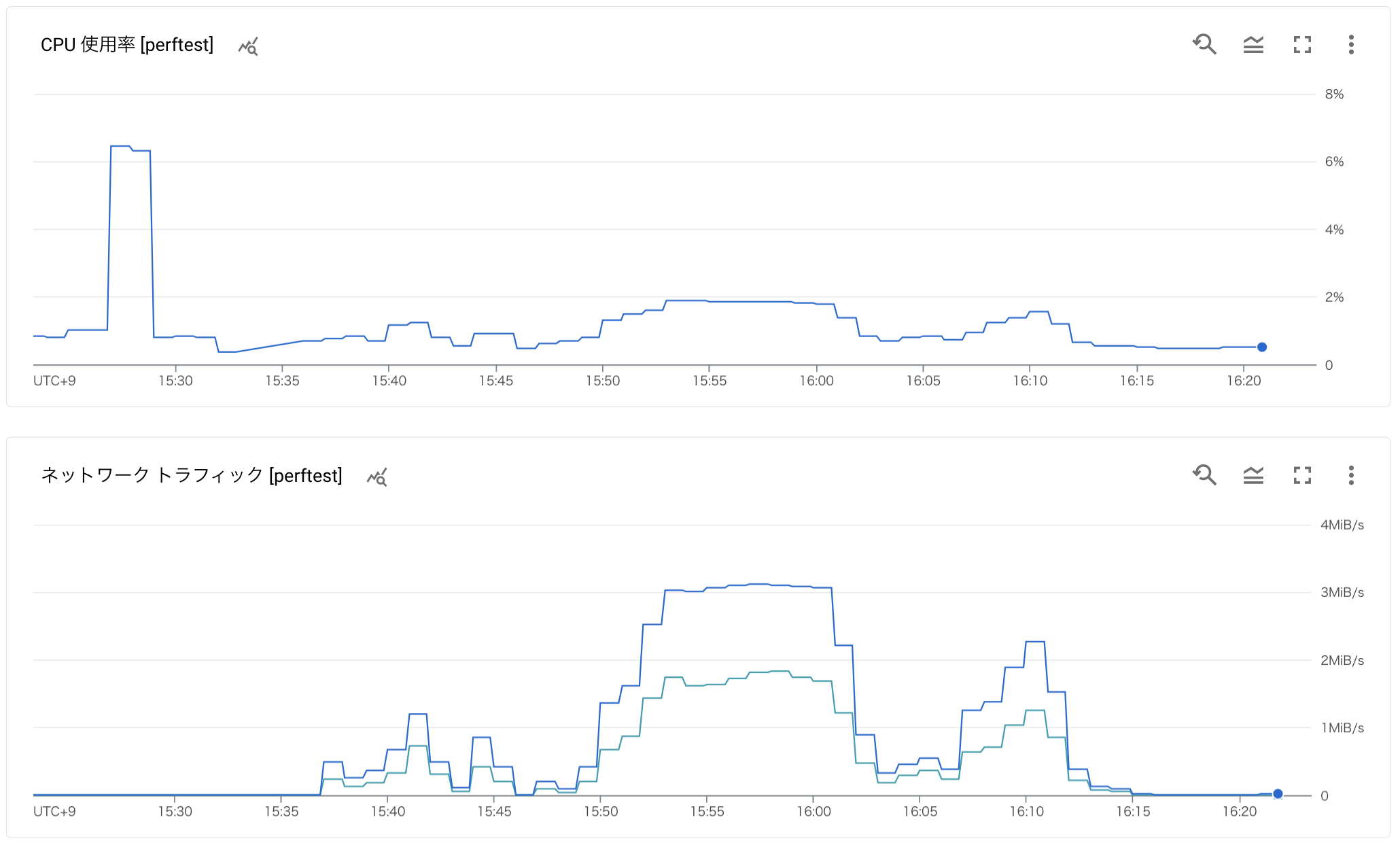 図8. Cloud Spanner計測中の負荷
図8. Cloud Spanner計測中の負荷
サービス毎の傾向
2つのサービスを比較すると、書込みと読出し、レスポンスタイムと時間あたりのリクエスト数について反対の傾向が見られ、興味深い結果になりました。
書込トランザクションについては、DynamoDBの方がレスポンスが平均で約31%速いのですが、同じ費用で処理できるリクエストの数はCloud Spannerの方が約1.8倍多くなりました。
整合性のある読出しでは、レスポンスタイムの平均はほぼ同じ(差が2%未満)ですが、処理できるリクエスト数はDynamoDBがCloud Spannerの2倍でした。
単純読出しでは、Cloud Spannerの方が平均レスポンスタイムが約37%速いのですが、処理できるリクエスト数はDynamoDBがCloud Spannerの5倍でした。
変動要因
今回の計測結果は飽くまで上に述べてきた条件での結果であり、特性を変化させる要因はいくつも考えられます。例えばプロビジョニングするキャパシティやデータ量、スキーマが挙げられます。特にCloud Spannerにはインターリーブと呼ばれるデータの配置方法があり、関連する複数のデータにアクセスする場合に効率が向上します。より正確な性能を知りたい場合には条件に合った計測が必要になるでしょう。
まとめ
ゲームアプリを想定した設定でDynamoDBとCloud Spannerのパフォーマンスを測定し、以下の傾向を発見しました。
- 書込トランザクションはDynamoDBの方が速いが、費用あたりのリクエスト数はCloud Spannerの方が多い
- 単純読出しはCloud Spannerの方が速いが、費用あたりのリクエスト数はDynamoDBの方が多い
参考になれば幸いです。