はじめに
こんにちは。インフラストラクチャー部のひらしーです。
今回は
PagerDuty を導入し、システムに異常が発生した際のアラート管理を改善した話を紹介します。
アラート管理改善前
解決すべき人へのエスカレーションが必要な問題発生時、以前は以下のような問題がありました。
通知手段がメールのみで、インフラチームのメンバーは全サービスのアラートを受け取って自分でフィルタリング・転送をする必要があり、問題のエスカレーション漏れや監視設定自体の見直しがされずに監視精度のばらつきが発生していた 過去のアラート情報が集約できておらず、問題の傾向把握や類似の障害の検索が困難だった PagerDutyについて
上記の問題を解決するため、メール運用のまま手法のみ改善する運用や内製ツールの開発を検討しましたがトライアルでチーム内での評価が高かったためSaaSのアラート管理ツールである
PagerDuty を採用しました。
インシデント管理
PagerDutyでの運用では解決すべき問題の単位を「インシデント」で管理します。インシデントはITマネジメントの分野ではITIL (Information Technology Infrastructure Library)で以下のように定義されています。
Incident ITIL Wiki#Incident Management より
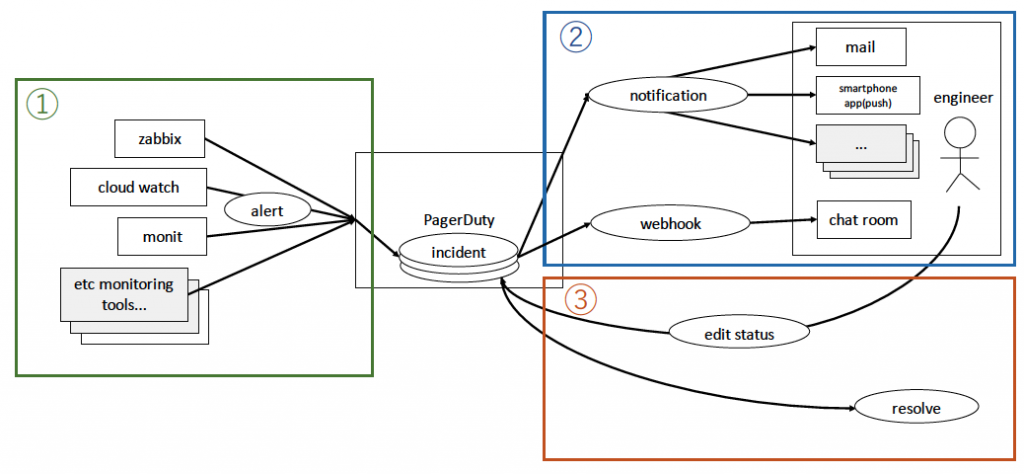
このインシデント管理を以下のように運用しました。
各種監視システム・ツールからアラートを発報 PagerDutyにインシデントが作られ、サービス担当者が自分で指定した各種メディア(mail,PagerDutyスマートフォンアプリ)に通知、同時にWebhook機能 にてエンジニアチームのChat Room(Chatworkを利用)に通知 サービス担当者がインシデントを確認、解決すべき人にエスカレーションし対応状況を追記していく、対応が完了したらインシデントをクローズ インシデントレビュー
適切なアラート流量での運用を保てないとサービスの健全性を失うので、監視設定を実施するエンジニアは以下のような観点で定期的にPagerDutyで管理しているインシデントをレビューしています。
Chat運用
インシデントレビューにてアラート流量がコントロールし易くなったためサービス単位でチャットツール(Chatwork)でのインシデント運用を導入しています。
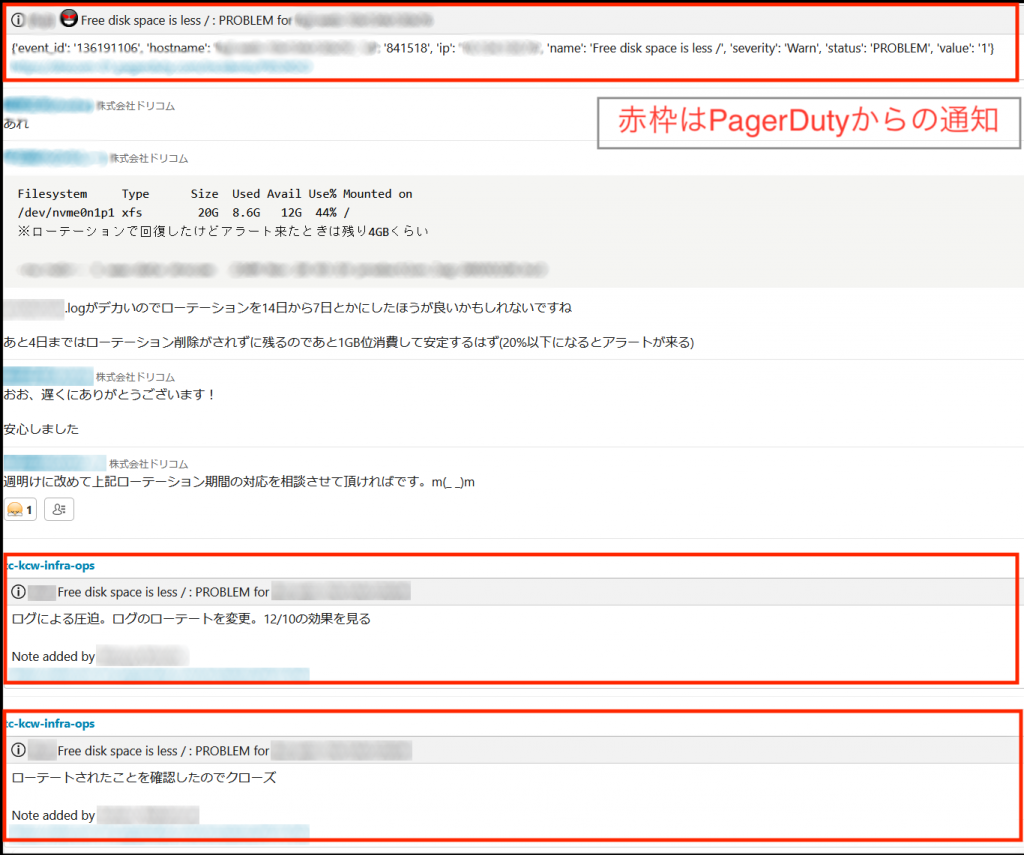
以下は昨年末発生したアプリケーションログのローテーション期間が長く、ディスク圧迫が発生した時のやり取りですが、PagerDutyのwebhook機能を利用しアラート発報からチームへの通知、エスカレーションから具体的な対応報告とスムーズにコミュニケーションできるようになりました。
改善結果
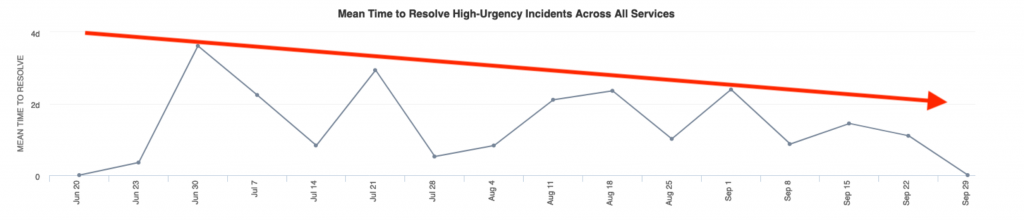
以下はPagerDutyの統計機能を利用して利用開始から3ヶ月間のインシデント解決までの期間の中央値を算出したグラフですが減少傾向になっています。また、本運用により見過ごしや漏れのあった監視設定が多く改善されました。
改善の余地がある点
以下は今回の改善でも課題を残したものとなります。
アラート流量の制御 上記インシデントレビューを実施していればある程度適切なアラート流量を調整することができますが、PagerDutyに送る前の監視ツールの仕様上コントロールが難しい場合がありました。 統一したインシデント管理運用サービス独自の管理ツールや評価指標がある場合、2重管理になったり、PagerDutyに独自の評価軸で管理することが困難というケースがありました。(例えばPagerDutyではアカウント単位でP1~P5という固定の優先順位しか設定できません) まとめ
PagerDutyによってアラート管理を改善した話を紹介させて頂きました。 異常検知は奥が深く、日々内部や外部の要因で変化するもので今後も気を抜かずに改善していきたいと思います。