
これはドリコム Advent Calendar 2020 の3日目です。
2日目は 広井 淳貴 さんによる「SwaggerCodegen で生成したコードを Unity へ導入した」です。
こんにちは、駆け出し golang エンジニアの Smith(@do_low) です。
golang レベルはミジンコくらいです。
ラノベならぬライトテックブログ担当ですが、もういい年なので記事タイトルは結構無理しています。
ある日、ぼんやりと TL を眺めていたら NestedText なるフォーマットの存在を知ったので、 golang の学習も兼ねて NestedText のパーサーを作ってみました。
https://github.com/dolow/nt-go
その実装の作業ログ的なものが本稿です。
この記事で得られるものは golang によるパーサー実装の流れのふんいきです。
楽しげなところをライトに紹介していきますので、golang やパーサー未経験の読者の皆様においても golang での構文解析を完全に理解したようなダニング・クルーガー効果を感じられたら幸いです。
待って、NestedText ってなによ?
突然ですよね。
NestedText は、構造化された文字列データを記述するためのフォーマットで、 YAML ほど複雜じゃなくて JSON みたいに構文が大変じゃないのが特色です。
github: https://github.com/KenKundert/nestedtext
Doc: https://nestedtext.org/en/latest/
JSON での下記のようなデータは
{
"dictionary": {
"key1": "str data",
"key2": [
"element 1",
"element 2"
],
"key3": "first line of text\nsecond line of text"
}
}
こんなかんじで書けます。
dictionary:
key1: str data
key2:
- element 1
- element 2
key3:
> first line of text
> second line of text
表現できるデータや構造は下記のとおりです。
| 種類 | 概要 |
|---|---|
| String | 改行を含まない文字列データ |
| Multiline Strings | 改行を含むことができる文字列データ |
| List | 配列形式で String や Multiline Strings を要素として持てる List や Dictionary をネストできる |
| Dictionary | K/V 形式で String や Multiline Strings を要素として持てる List や Dictionary をネストできる |
いずれもデータ種別に型の概念はなく、全て文字列として扱います。
また、階層構造は YAML の様にインデント幅で表現します。
すこし複雜な例だとこんな感じです。
smith:
age: 37
address:
> Japan, Tokyo
> Suginami
family:
-
relation: wife
age: inappropriate question for lady
favorites:
- sweets
- reading
このパーサーを golang で書こうかなって思った時、 10秒ググって golang での実装は出てこなかったので、多分これが世界初の NestedText パーサの golang 実装でしょう。
そうじゃなくてもそういうことにしておくと、モチベーションに良い効果が出るので推奨します。
ぼくがかんがえたさいきょうの I/F
何を作るにしても、 I/F を考えているときが一番楽しいですよね。
ただ、今回はパーサーですので玄人好みのシンプルな I/F にまとまりました。
ふつうにユーザが求めそうな I/F
encode/json に見られるように、golang ではデータスキーマにメタ情報を付加することで、外部入力からのマーシャリングが可能です。
逆に言うと、 スキーマがわからなければわからないなりに NestedText での記述内容を表してデータとして扱える dto を返さなければなりません。
つまりユースケースとしては、dto スキーマがわかっているケースとわからないケースの大まかに 2種類を考える必要があります。
今回は、スキーマがわからないデータを扱う場合の dto を Value という構造体として定義しました。
その他の I/F は下記の 4種類です。
// NestedText のコンテンツ情報を有する dto
type Value struct {
}
// NestedText 形式の byte スライス入力値を *Value インスタンスに持たせる
func (*Value) Parse(content []byte) error
// *Value の保持している値を NestedText 形式の string に変換する
func (*Value) ToNestedText() (string, error)
// NestedText 形式の byte スライス入力値を任意 dto にマーシャルする
func Marshal([]byte, interface{}) error
// 任意 NestedText dto 入力値を NestedText 形式の byte スライスに変換する
func Unmarshal(interface{}) ([]byte, error)
関数の I/F のバリアントとして、引数に []byte ではなく string を受けるものやレシーバの有無も考えましたが、後で変えるコストは低いので一旦この形で進めています。
未知の型を受ける際に利用可能なインターフェース。
void ポインタのような印象ですが、キャスト可能かどうかの検証や、 型に応じた switch が可能です。
func (i inerface{}) {
// キャストの検証
number, ok := i.(int)
// 型に応じた switch
switch t := i.(type) {
case int:
fmt.Println(t)
default:
return
}
}
データや構造の表現は硬派にキメる
先ほど決めた I/F の一つ、Parse() では Value を返します。
Value からは NestedText のデータ構造やデータそのものが取得できるべきです。
Value が保有するものが何なのかが判断できる識別子と、その実体のコンテナとなるフィールドを定義しましょう。
今回は下記のように人間に優しめな感じで定義しています。
複数行の文字列を表すデータの命名は MultilineStrings だと長いので Text としています。
// NestedText のコンテンツの種類を表現する型
type ValueType int
const (
ValueTypeUnknown ValueType = iota
ValueTypeString
ValueTypeText
ValueTypeList
ValueTypeDictionary
)
// NestedText のコンテンツ情報を有する dto
type Value struct {
Type ValueType
String string
Text []string
List []*Value
Dictionary map[string]*Value
}
ValueType である ValueTypeUnknown などの const 変数は enum として扱います。
const で宣言された変数に利用可能な識別子で、インクリメントする整数を返します。
enum を表現したい場合に便利です。
また、下記のリンク先のように演算に用いることもできます。
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota)
MB
GB
TB
PB
EB
ZB
YB
)
硬派にキメましたが、反省点はいくつかあります。
データの実体と構造の識別子が分かれていないのは若干気持ち悪いですし、 Text は []string ではなくて string のほうが良かったんじゃないかという思いがあります。
でも硬派でしょ?
この構造体を用いる場合、値を出力する処理は下記のようになります。
とても硬派ですよね?
func ShowContent(dto *Value) {
switch dto.Type {
case ValueTypeString:
fmt.Println(dto.String)
case ValueTypeText:
for _, line := range dto.Text {
fmt.Println(line)
}
case ValueTypeList:
for _, child := range dto.List {
ShowContent(child)
}
case ValueTypeDictionary:
for _, child := range dto.Dictionary {
ShowContent(child)
}
}
}
男のロマン、マーシャル
スキーマが分かっている場合の扱いは、 encode/json の MarshalJson でもおなじみですね。
構造体のフィールドにタグを付けてあげればいい感じにマーシャルされるようにしたいと思います。
こんな NestedText も、
name: smith
profile:
address:
> Japan, Tokyo
> Suginami
favorite: Natto
この構造体定義でマーシャルできるようにする、これはかっちょいい。
type Profile struct {
Address MultilineStrings `nt:"address"`
Favorite string `nt:"favorite"`
}
type Person struct {
Name string `nt:"name"`
Profile *Profile `nt:"profile"`
}
マーシャルしたらこんな感じにデータが扱える。
// 想定する動作
p := &Person{}
Marshal(content, p)
fmt.Println(p.Name) // "smith"
fmt.Println(p.Profile.Address[0]) // "Japan, Tokyo\n"
fmt.Println(p.Profile.Address[1]) // "Suginami"
fmt.Println(p.Profile.Favorite) // "Natto"
ここまでで I/F やちょっとした要件が定まりました。
オレオレモジュールを妄想する至福の時間でしたね。
ここからが本当の地獄です。
地道に実装
NestedText の構文解析
あー、そういえば構文解析って真面目にやったことなかったな、ってこの段階になって気付きます。
趣味プログラミングだし、そういうちょっと無防備な感じで取り組んでいます。
幸い、NestedText にはドキュメントが用意されています。
https://github.com/KenKundert/nestedtext/tree/master/doc
あとは NestedText の気持ちになってバイト配列を読むことで仕様理解を進めます。
注意深く構文を観察すると、単一行でデータ構造や値が読み取れることがほとんどであることが分かります。
その行がどんな意味を持つ構文なのかを表す文字列(以下、トークン)がほとんどすべての行の先頭に位置するためです。
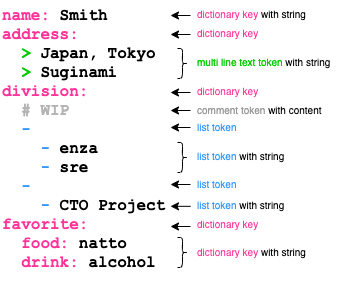
図: 先頭のトークンで構文が判断できる
解析は下記の流れで処理しようと思います。
- 入力値から一行ずつ読み込む
- 読み込んだ行を先頭から走査する
- 最初に出現する意味のある文字列を検出
- トークンであるかを判断して、トークンに応じたその後の値や構造を解析
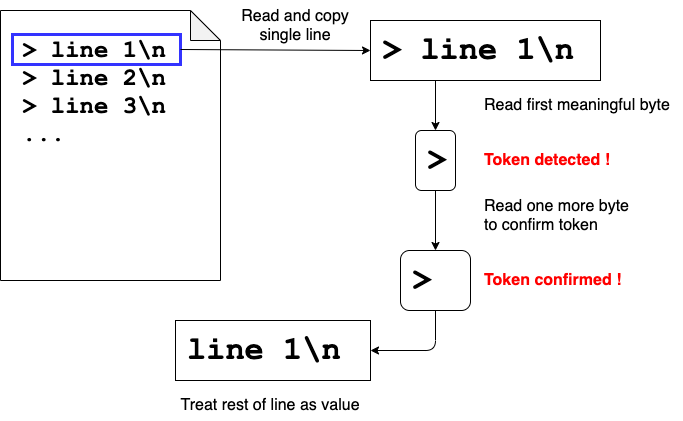
図: Multiline Strings の解析例、2バイト検証する理由は後述
とにもかくにも 1行単位で読み込む必要があるため、まずは入力値から1行を読み込んでそのコピーを返す関数を用意しました。
行の解析はその後じっくり行います。
読み込みながら解析する選択肢もありましたが、まずは処理をわかりやすくするために1行の再走査のオーバーヘッドを許容しています。
type ByteReader interface {
ReadByte() (byte, error)
}
func readLine(buffer ByteReader) (line []byte, err error) {
var b byte
for err != io.EOF {
// 1.
if b, err = buffer.ReadByte(); err != nil && err != io.EOF {
break
} else if b == EmptyChar {
break
}
line = append(line, b)
// CRLF can be ignored under parsing data structure
// It only should be considered under parsing multiline strings
// 2.
if b == CR || b == LF {
break
}
}
return
}
- golang の
bytes.BufferのReadByte()で入力値を 1バイトずつ読み込む - データ構造上、改行コードは重要ではないため CR も LF も行の終端として扱む
行の読み込みは、改行コードの出現以外に、バッファの終端に到達して io.EOF が返されたときも終了させます。
io.EOF は、リーダーの読み取りがファイルの終端に到達した場合にエラーとして返されます。
そのため、正常系処理におけるエラーチェックは、エラーが nil ではないことと、 io.EOF でないことを検証する必要があります。
readLine() において、引数の buffer は ReadByte() (byte, error) のシグニチャを持つとする interface で定義しています。
readLine() にとっては buffer が bytes.Buffer である必要性がないためです。
これは、多様なリーダーを受け入れ可能にすると同時に、テスタビリティを高める効果もあります。
// エラーをテストするための ByteReader 実装
type ErrorBuffer struct {
ByteReader
}
func (ErrorBuffer) ReadByte() (byte, error) {
return 0x00, errors.New("error for test")
}
// エラーのテスト
func TestReadLine(t *testing.T) {
_, err := readLine(&ErrorBuffer{})
assert.NotNil(t, err)
}
bytes.Buffer には他にも、任意のデリミタを指定してのバイト配列読み出しができる ReadBytes という関数があり、改行コードを渡すことで行を一気に読み込むことも可能です。
が、今回は CRLF を考慮して 1バイトずつ読み出しています。
改行コードはデータ構造上は重要ではありませんが、Multiline Strings のデータを扱うときのみ、 CR は文字列の一部として忠実に含める必要があります。
これについては後述します。
行が抽出できたらその行を 1バイトずつ読み込み、トークンの出現を検出します。
NestedText においてのトークンとは下記のようなもので、 Dictionary のキーのデリミタのように行の途中で出現するものもあります。
| トークン | 意味 |
|---|---|
| \n | 改行コード(LF) |
| # | コメント行の始まり |
| > + (‘ ‘ or \n) | Multiline Strings 行の始まり |
| – + (‘ ‘ or \n) | List 要素の始まり |
| : + (‘ ‘ or \n) | Dictionary キーのデリミタ |
また、トークンではないけれども特殊な意味を持つ文字列がいくつかあります。
| 文字列 | 意味 |
|---|---|
| \t | タブ文字、インデントに用いられている場合はエラー扱い |
| トークンや上記以外の文字列 | Dictionary のキー もしくは String |
行の解析時は、行頭からスペース以外で最初に出現する文字を意味のある文字とし、その文字のインデックスから 2バイトを検証して行の種別を推測します。
2バイトである理由は、このデータ範囲が何なのかを識別するためのトークンの長さが NestedText の場合は 2バイトであるためです。
たとえば Multiline Strings のトークンの1バイト目 (>) が行頭で確認されたとしても、その直後にスペース以外の何らかの文字列が出現するようであれば、それは Multiline Strings トークンとしては扱いません。
エッジケースですが、下記のような行は Dictionary のキーと値として扱われます。
>this is not multiline strings : but dictionary!
トークンの知識を得て行単位での読み出し方法も確立したので、なんかもう実装できる気がしますね。
この時点で気持ち的には完成したも同然です。(進捗 0% です)
トークン別の解析
Multiline Strings
Multiline Strings は、 NestedText の中でも比較的シンプルな構成です。
Multiline Strings を表すトークン > + ‘ ‘ が出現した場合、下記の条件が続く限りは Multiline Strings のデータとして読み込むことが出来ます。
- 解析中の行でトークンが初めて出現した際のインデント幅が保たれている
- 解析中の行は
Multiline Stringsのトークンから始まっている - 改行やインデントだけの何もない行やコメント行は無視する
Multiline Strings は値であるため他のデータ構造をネストすることもなく、一行ずつ読み込む手法との相性は悪くありません。
複数行にわたる解析の流れは下記のようになります。
- 解析中の
Multiline Stringsの最初の行のトークンのインデックスを記憶しておく(トークンインデックス) - 解析中の行の先頭から、最初に出現する意味のある文字とそのインデックスを取得する
- インデックスがトークンインデックスより小さければ、親要素に戻ったとみなして解析終了
- インデックスが子トークンインデックスと一致していれば解析続行、一致していなければエラー
- トークンの次のインデックスから改行コードを含めた行の終端までを読み取り、一行分のデータとする
注意点として、 CRLF の考慮があります。
少し前に掲載した一行ずつ読み込む readLine() 関数では CR の出現も行の終端とみなします。
もしも CRLF が出現した場合、 readLine() は CR で終わる行に引き続いて LF のみ含む行を返します。
つまり Multiline Strings として行を解析中に LF のみを含む長さ 1 の行が返された場合には、直前の行の終端が CR であるかどうかを検証することで CRLF を正しく同一行に含めることができるようになります。
if len(currentLine) == 1 && currentLine[0] == LF {
if len(d.Text) > 0 {
lastLine := d.Text[len(d.Text) - 1]
if lastLine[len(lastLine) - 1] == CR {
d.Text[len(d.Text) - 1] += string(LF)
}
}
}
Multiline Strings で肩慣らししたら、なんだか他の Dictionary や List も楽勝な気がしますね。
根拠のない自信は時として本当に実力を発揮します。
Dictionary
NestedText の構文解析において、 Dictionary を制するということは全てを制することと同義です。少なくとも、実際にやってみた感じだとそんな体感です。
行の最初に出現する意味のある文字列がトークンでない場合、Dictionary の気配が感知できます。
しかしその後にキー文字列のデリミタが検出されるまでは String ではないことの確証が持てません。
String は必ず Dictionary や List の値として同じ行に置かれる、というルールがあるため、行の最初に出現する意味のある文字列が String の一部である場合は明確なエラーです。
我々は異常系のある世界線の住人ですので、エラーとなる String はキチンと検知しなければなりません。
# Dictionary のキーに紐ついている
key1: value
# ネストした Dictionary のキーに紐ついている
key2:
key_for_empty_str:
# これは許容されない
key3:
lonely string
# List も同様
- value
# もちろん、List もネストできる
-
- value
# やっぱりエラー
-
lonely string
# こいつぁたいへんだ
-
key1:
- value
key2:
key3:
-
- もうわけわからんけど構文は正しい
下記の条件を満たした場合に、その行は有効な Dictionary のキーを含むと判断できます。
- 解析中の行の最初の意味のある文字列がトークン以外で始まっている
- 解析中の行は
Dictionaryキー文字列デリミタのトークンを含む - キー文字列はシングルクォートやダブルクォートで囲むことができる(!)
さて、新キャラが出てきましたね。
実は NestedText はキー文字列の指定にクォート文字が使えます。
キー文字列にスペースを含めたい場合は、このクォート文字を用います。
公式のテストケースには、下記のようなめちゃめちゃ意地悪なキーもあったりして。
" " key12 : " ": value 12
JSON 的にはこういう解釈になるようです。
{ " \" key12 : \" ": "value 12" }
非常に熱い展開ですね、テンション上がりまくりです!
幸い、NestedText の場合はキーに改行を含めることは許容されていません、そのため単一行を調べるだけでコトは比較的に穏便に済ませることが可能です。
また、エスケープシーケンスもないため命拾いしています。
そんなこんなで悪夢に一晩うなされた結果、クォートも利用可能な Dictionary のキー文字列は下記のルールを満たすということが導出できました。
- クォート始端は解析中の行の最初の意味のある文字として出現する
- クォート始端と同じクォートが最後に出現したインデックスがクォート終端
- クォート終端のインデックスより後ろに出現する最初の
Dictionaryキー文字列デリミタのトークンが有効なトークン - クォート始端とクォート終端で囲まれたキー文字列の途中にあるクォートはキー文字列を構成する値として扱い、特別な意味を持たない
- クォート始端とクォート終端で囲まれたキー文字列の途中にあるトークンはキー文字列を構成する値として扱い、特別な意味を持たない
- クォート終端から
Dictionaryのキーデリミタのトークンまでのスペースはキー文字列として扱わず、意味のない文字として無視する
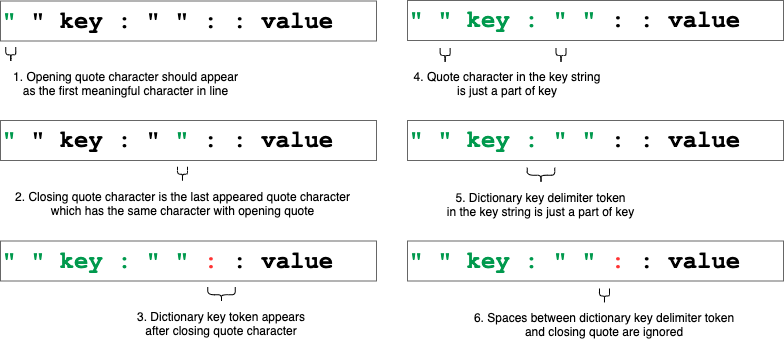
図: 多分、チーム開発だとこういう絵が必要になる
謎解きとか脱出ゲームも分かる前は悶々としますが、分かってしまえばなんてことはないですよね。
あとはコードに落とし込むだけですが、今回は関数を2つに分けて二段構えで処理させました。
- 行頭の意味のある文字のインデックスからデリミタまでのキー文字列範囲の抽出処理
- キー文字列範囲からスペースやクォートを取り除くサニタイズ処理
前者のキー文字列範囲を抽出する関数は下記のようになっています。
func detectKeyBytes(line []byte) ([]byte, int) {
var char byte
meaningfulIndex := NotFoundIndex
quoteClosingIndex := NotFoundIndex
delimiterBeginIndex := NotFoundIndex
delimiterEndIndex := NotFoundIndex
quote := EmptyChar
for index := 0; index < len(line); index++ {
// 1.
char = line[index]
if quote != EmptyChar && char == quote {
quoteClosingIndex = index
}
if meaningfulIndex == NotFoundIndex && !unicode.IsSpace(rune(char)) {
meaningfulIndex = index
if char == Quote || char == DoubleQuote {
quote = char
}
}
if char == DictionaryKeySeparator {
// 2.
if index > quoteClosingIndex && (delimiterBeginIndex == NotFoundIndex || delimiterBeginIndex < quoteClosingIndex) {
// ':' with line break
if index >= (len(line) - 1) {
delimiterBeginIndex = index
// 3.
delimiterEndIndex = index + 1
} else {
// ':' with space
if unicode.IsSpace(rune(line[index+1])) {
delimiterBeginIndex = index
// 3.
delimiterEndIndex = index + 2
}
}
}
}
}
if delimiterBeginIndex == NotFoundIndex {
return nil, NotFoundIndex
}
// 4.
return line[meaningfulIndex:delimiterBeginIndex], delimiterEndIndex
}
- 入力値の行を1バイトずつ走査
- クォート出現や
Dictionaryキー文字列デリミタのトークン 出現のインデックスに基づいて、キー文字列範囲を確定 Dictionaryキー文字列デリミタのトークン直後は改行である可能性を考慮し、値が始まるインデックスを調整- 返り値はキー文字列範囲として切り出したスライスと、キーに対する値が始まるインデックス
クォート外でデリミタのトークンの出現が確認されても行の走査を終了しないところがポイントです。
行の終端まで、最後に出現するクォートとデリミタのインデックスを探し続ける動作にしています。
もう一つのキー文字列範囲のサニタイズ関数は、クォート終端以降のスペースを取り除いた上で、クォート始端と終端を取り除くだけの片手間です。
こたつでみかん食べながらネトフリ見るくらいの片手間なので、コードの掲載は割愛します。ネトフリ入ってないけど。
さて、キー文字列が検出できたのはいいのですが、デリミタの直後に String がぶら下がっている可能性があります。
こいつも併せて検出しましょう。
ちなみに、下記のようにキーの直後に改行が置かれている場合 String ではありません。
not_a_string:\n
というのはウソです、空文字の可能性があります。
not_a_string:\n sorry: ああ、うそだぜ!だがマヌケは見つかったようだな!
NestedText に String の終端を表すトークンがあればよいのですが、そんなものはありません。
このキーがネストしているかどうかを判断するには実際に次の行を読み込む必要があります。
でも読み込んでいる最中にまた疑わしき行が出てきたら・・・?
not_a_string:\n
# またかよ!
is_this_string:\n
こんな調子では一々処理していると身が持たないので、ネスト開始から終了までの []byte を子要素の Value に Parse() させます。
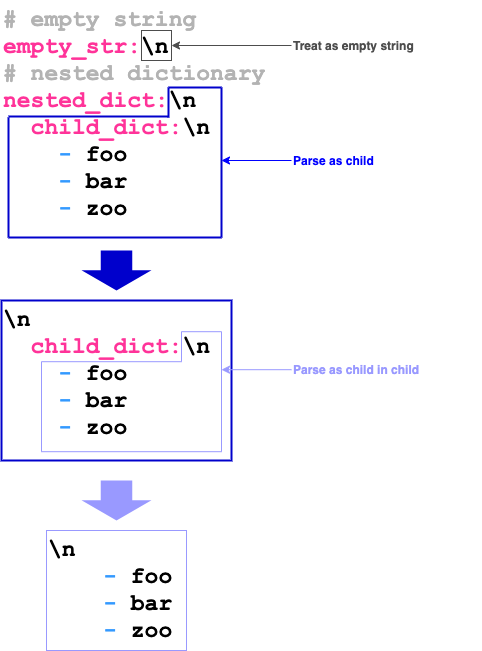
図: より小さい NestedText に切り出していく
再帰構造は、頭よさそうだけどパフォーマンスが気になりますね。
今回はまず正常系を実装して、テストを通してから最適化しようと決めています。
技術的負債の借り入れ判断です。
再帰構造にすると割り切ってしまえば、構文の解析は第一階層のみに集中できます。
List
Dictionary を倒した私にとって List は Dictionary の劣化版でしかありません。
List にエンカウントしても戦闘にならずに触れただけで倒せるレベルです。
List はキー文字列を持たないので更に楽ちんです。
処理はほぼ Dictionary と一緒なので割愛します。
修行の成果を見せてやったぜ!
さて、ここまででデータ種別ごとのパース処理ができました。
スキーマの知識がない NestedText データのパースはもう実現できます。
パース済のデータを文字列として吐き出す
すでに何かしらの値が詰められている Value から NestedText 文字列を返す関数を実装します。
その I/F は既に冒頭で ToNestedText() と定めています。
こちらはパースと比べて複雜ではないので、正直に言うとそこまでテンションは上がりません。
子要素を再帰呼び出しして、ネストの深さに応じてインデントを付けるだけです。
値が String であるかどうかに依存する改行の扱いだけがちょっと曲者です。
func (d *Value) ToNestedText() string {
str := ""
if d.IndentSize <= 0 {
// default size
d.IndentSize = UnmarshalDefaultIndentSize
}
baseIndent := fmt.Sprintf("%*s", d.IndentSize*d.Depth, "")
switch d.Type {
case ValueTypeString:
str = d.String
case ValueTypeText:
for i := 0; i < len(d.Text); i++ {
str = fmt.Sprintf("%s%s> %s", str, baseIndent, d.Text[i])
}
case ValueTypeList:
for i := 0; i < len(d.List); i++ {
// TODO: user prefered line break code
dataLn := string(LF)
child := d.List[i]
if child.Type == ValueTypeString {
dataLn = string(Space)
}
// TODO: linear recursion
str = fmt.Sprintf("%s%s-%s%s\n", str, baseIndent, dataLn, child.ToNestedText())
}
case ValueTypeDictionary:
it := 0
for k, v := range d.Dictionary {
dataLn := string(LF)
if v.Type == ValueTypeString {
dataLn = string(Space)
}
str = fmt.Sprintf("%s%s%s:%s%s\n", str, baseIndent, k, dataLn, v.ToNestedText())
it++
}
}
return str
}
本稿では再帰処理の要素が多分に含まれています。
プログラミング言語には、コンパイル時に末尾最適化を行ってくれるものもあるようですが、 golang は最適化しないような旨がコミュニティに記載されています。
(リンクは 9年前とかなり古いですが)
https://groups.google.com/g/golang-nuts/c/nOS2FEiIAaM/m/miAg83qEn-AJ
なにはともあれ、ここまでで未知のスキーマの NestedText の入力と出力を取り扱うことができるようになりました。
これでモジュール然とすることができます。
ねんがんの Marshal をてにいれる
裏ではリフレクションという大人の火遊びの匂いを感じさせる、憧れの Marshal() さん。
構文解析だなんだ仰々しく言っても、結局はこれがやりたかっただけです。なんかかっこいいし。
実はここまで書いたパース機能は Marshal() でも利用するつもりです。
入力値を一度未知のスキーマとして dto にしてしまい、後から確実に要素をタグ情報で索引できるようにします。
構造体のフィールド定義では nt タグを用いて NestedText のマーシャル対象であることを示します。
SomeField string `nt:"some_field"`
Marshal() 関数は任意の構造体を interface{} として引数に取るため、予め引数の型情報を静的に知り得ているわけではありません。
ランタイムで構造体の情報を知るためには reflect モジュールを利用します。
憧れの Marshal() さんなどともてはやしつつも、モジュール名から JIT コンパイルを想起して拒否反応が出てしまいますね。 (私は)
マーシャル処理には reflect で取得できる以下の情報が必要です。
- フィールド一覧
- フィールドの型
- フィールドの実体
- タグ情報
これらを標準出力するだけなら下記のようになります。
// 1.
func ShowNtTag(v interface{}) {
typ := reflect.TypeOf(v)
var val reflect.Value
if typ.Kind() == reflect.Ptr {
// 2.
val = reflect.ValueOf(v).Elem()
// 3.
typ = typ.Elem()
} else {
val = reflect.New(typ)
}
// 4.
for i := 0; i < typ.NumField(); i++ {
// 5.
fieldInfo := typ.Field(i)
// 6.
fieldRef := val.Field(i)
// 7.
tagValue := fieldInfo.Tag.Get(MarshallerTag)
fmt.Println(tagValue, fieldRef)
}
}
func main() {
p := &Person{}
ShowNtTag(p)
}
- 入力値にはどのような構造体が渡されるかはわからないので
interface{}を取る - 引数がポインタであった場合はポインタ参照先を
reflect.ValueのElem()で取得する - 引数がポインタであった場合はポインタ参照先の
reflect.Typeを取得するために、Elem()で取得する - イテレーションで用いている
NumField()は、レシーバが構造体のreflect.Typeでない場合は panic を起こす (今回はハンドリングしない) - フィールドの静的情報は
reflect.TypeのField(int)で取得 - フィールドの実体は
reflect.ValueのField(int)で取得 - タグ情報は
reflect.TypeのField(int)で取得できたStructFieldの Tag フィールドから取得
引数の interface{} は、引数宣言でポインタ (*) を付けなくても参照が渡される可能性があります。
さて、各フィールドの実体が取得できたら、フィールドに値を代入するだけです。
value.Field() で取得できた reflect.Value に対しての値のアサインは、値の種別によってやり方が異なります。
// 文字列の割当
s := "hello reflect!"
fieldRef.SetString(s)
// 文字列の参照の割当
fieldRef.Set(reflect.ValueOf(&s))
// 構造体の割当
strcutRef := reflect.New(fieldType)
fieldRef.Set(strcutRef.Elem())
// 構造体の参照の割当
fieldRef.Set(strcutRef)
// スライス要素の追加
fieldRef.Set(reflect.Append(fieldRef, reflect.ValueOf("hello")))
// 新しいスライス要素を割当
newSlice := reflect.MakeSlice(fieldRef.Type(), fieldRef.Len(), fieldRef.Cap())
newSlice = reflect.Append(newSlice, reflect.ValueOf(s))
fieldRef.Set(newSlice)
reflect.MakeSlice は、新しいアドレスにあるスライスを返すことに注意が必要です。
いつもの append() の感覚で fieldRef への再代入を行ってしまうと、本来値をセットしたかったフィールドへの参照が失われてしまいますので注意が必要です。
普段使いの append() でモヤっとする部分の正体は再代入だと思います。
配列のメモリ確保の仕方を考えるといたしかたない挙動とも言えるでしょう。
配列は、名前の通り連続性のあるメモリアドレスに配置されますが、配列を拡張したい時、つまりキャパシティを拡張したいときに、必ずしも拡張したい長さの分だけ後続のメモリアドレスが空いているとは限りません。
リファレンスでは、 append() 後のスライス長に対してキャパシティが足りなければ、新たな配列が裏で割り当てられるとされています。
golang.org / append
https://golang.org/pkg/builtin/#append
tour.golang.org / length and capacity
https://tour.golang.org/moretypes/11
reflect 周りの処理は、すでに encoding/json モジュールでここでやりたいことがやり尽くされているので、参考にしてみてもいいかもしれません。
https://github.com/golang/go/tree/master/src/encoding/json
構造体のフィールド情報の走査ができて、 reflect を利用した値の代入手法がわかれば、もう Marshal() は出来たも同然ですね。
reflect の扱いにもっと手こずるかと思いましたが、意外と半日くらいで終わりました。
Marshal() 関数は記事に掲載するにはちょっと長くなってしまうため github の方を参照いただければと思います。
Unmarshal もわすれずに
Unmarshal() は ToNestedText() とほぼ勝手が一緒ですが、NestedText の仕様通りに処理しなければならないという制約があります。
例えば golang 上で string であるフィールドだったとしても、値に改行を含んでいる場合は Multiline Strings として出力しなければなりません。
逆に Multiline Strings のトークンで表現されている NestedText のデータのマーシャル先が string であった場合は、改行コードも含めた string にしなければならないでしょう。
同様に、 NestedText 上で String として表現されているキーのマーシャル先が []string であった場合は、その []string の要素としてマーシャルする必要があります。
これらは一見煩雑ですが、string 中に改行コードが含まれるかどうか、あるいは Value の Type で処理を分けられます。
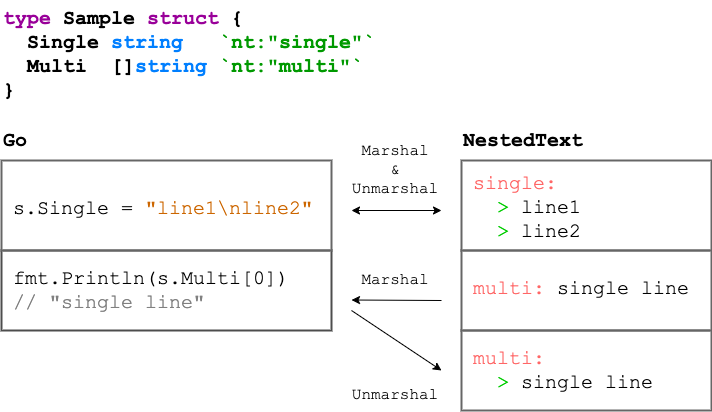
図: 素直に変換すりゃいいってもんじゃない
Multiline Strings と、 String を要素に持つ List は NestedText 上では別物ですが、今回の Value の定義だといずれも Marshal() 後は []string となります。
逆の流れも考慮してみましょう。
Unmarshal() が可能な構造体フィールドの型が []string である場合、 List と Multiline Strings のどちらとして出力すれば良いかわかりません。
これは問題なので、このメタ情報もタグに含めるようにします。
(ああ、やっぱり Value の Text は string にすべきだったかなぁ)
メタ情報で言うと、値が空だったり nil のフィールドは、そもそもキーを吐き出したくないケースもあると思います。
これは encode/json に倣って omitempty に対応できるようにします。
メタ情報で指定する omitempty などはフラグとして扱えるようにしました。
これで、追加削除の対応も安くなりそうです。
func getTagFlagFromTagValue(tagValues []string) (flag int) {
for i := 1; i < len(tagValues); i++ {
switch tagValues[i] {
case MarshallerTagMultilineStrings:
flag |= MarshallerTagFlagMultilineStrings
case MarshallerTagOmitEmpty:
flag |= MarshallerTagFlagOmitEmpty
}
}
return
}
Unmarshal も詳細は github の方をご参照下さい。
TDD ではないけれど
実装の全体像が出てきたら、ユニットテストに対応していきます。
Parse() や Marshal() などの主要な関数は、今後の最適化も踏まえて最初から関数の粒度を細かくするのは避けてきました。
TDD とは言い難いですが、大きな正常系の実装とその I/O を検証するテストを書いて初めて、リファクタとテストの追加を進めていくスタイルです。
また、公式のテストケースでは NestedText のパースのみ扱うため、 ひとまず動く Parse() の実装の完了が必要だった、という事情もあります。
テストライブラリは github.com/stretchr/testify/assert というモジュールの取り回しが良かったのでそちらを使っています。
テスト対象の関数のパラメータは NestedText 文字列のみなので、テストはかなり書きやすい方でした。
仕様を表現する用途としても機能しそうです。
func TestParse(t *testing.T) {
var data []byte
subject := func() (*Value, error) {
value := &Value{}
err := value.Parse(data)
return value, err
}
t.Run("string", func(t *testing.T) {
t.Run("regular string", func(t *testing.T) {
data = []byte("plain text")
t.Run("should cause RootStringError", func(t *testing.T) {
_, err := subject()
assert.NotNil(t, err)
assert.Equal(t, RootStringError, err)
})
})
})
}
いともたやすく用意されるえげつないテストケース
公式のテストケースはかなり試されます。
たとえばこういうの。
key::
:-#"\">:: :-#'\'>::
このテストに対応するだけでエッジケースはかなり潰せます。
公式のテストケースに対応する頃には基本実装とそのテストケースができていたので、リファクタや仕様誤認による修正のコストは低く抑えられた体感です。
テストケースには list_1 とか dict_10 みたいな名前が付いてるので、感覚的にはステージクリア型のパズルゲームでした。
今後のアプデによるステージ追加が期待されます。
えげつないテストケースたち: https://github.com/KenKundert/nestedtext_tests
NestedText は、先日 v1.0 が出たばかりとあって流石に流れが早いですね。
テスト頑張ったし、CircleCI で go test 回しとこう
せっかくテストを書いたので、カジュアルに CircleCI で回るようにしておきたいと思います。
CircleCI の設定では golang 環境の docker イメージを指定しますが、デフォルトでは golang バージョン 1.9 が指定されていました。
バージョン 1.9 は go mod の無い世界ですが、さすがに今からそこには戻れないので、 1.15 に指定を変更しています。
executors:
go_1_15:
docker:
- image: circleci/golang:1.15
working_directory: /go/src/github.com/dolow/nt-go
ジョブ自体は golang だからといって特別なことは必要ない感じです。
# 公式のテストケースを取得
- run: git submodule update --init --recursive
# golang 依存モジュールのダウンロード
- run: go mod download
# テスト回す、カバレッジも出しちゃうぜ
- run: go test -v -coverprofile=coverage.txt .
カバレッジも codecov にアップします。
orbs: codecov: codecov/codecov@1.1.3
- codecov/upload:
file: ./coverage.txt
修正が入ったバージョンは 1.1.3 として利用可能で、 今回の設定でも利用しています。
CircleCI の設定の全容はコチラ。
全部 build 配下で横着しているのはスルーして下さい。
https://github.com/dolow/nt-go/blob/main/.circleci/config.yml
気付き・学び
CI のあるべきを思い出す
趣味プログラミングでモジュール然としたものを作るのは、年単位で久しぶりです。
個人開発だからといっても、やっぱり CI でテストが回っていると安心しますね。
少し前は Unity などのゲームエンジンや HTML5 ゲームライブラリ周辺の開発を中心に行っていたため、そもそもテスト出来るものやテスト手法が今回のパーサーのように単体実行できるモジュールとは大きく異なり、かなりの制約がありました。
逆に言うと、ポータビリティが高かったり、依存関係の少ない技術の開発体験が非常に良いことを再発見するきっかけとなり、自分の中での CI のあるべきの状態がアップデートできました。
品質担保の初期コスト
golang のテストは、テストコードの表現力こそ物足りなく感じますが、カバレッジやベンチマークが CLI オプションで取れるので非常に体感が良いです。
なんかこう、ベンチ取ろうって気持ちになります。
ベンチなど、技術品質の指標の重要度や価値はわかっていても、そのアクセシビリティの低さは開発現場ではコストと同義となります。
Web フロントエンドでカバレッジを取ろうとした時、 golang ほどの簡便さは残念ながら体験しませんでした。
それはしょうがないものとわかりつつも、やっぱり「カバレッジを取ってみる」という最初のアクション自体に技術選定や検証を要するというコストが生まれます。
言語レベルでこれらがサポートされているのはやっぱり強いなと感じる反面、そういった環境が提供されていない言語やフレームワークに対しては、組織的なデファクトが必要なのかなと感じます。
組織的に使い古している技術であればデファクトは確立されていますが、新規事業や新規技術領域においては、まず理想の開発環境とのギャップを意識したいところです。
まだまだ踏んでいない golang の裾野
golang で一気通貫で何かを作るのもほぼ初めてです。
今回はチーム開発ではありませんでしたが、オンボードに必要な情報やセットアップを行うべきかなど思索を巡らすにはちょうど良い機会でした。
ポインタがなかったり、静的型付けではない、あるいは AOT コンパイルの概念が無い言語出身のエンジニアは、 golang で相当苦労するんじゃないかなと思います。
私自身は C/C++ が好きなのでむしろとっつきやすいのですが、それが故に躓きどころに鈍感になっている自覚もあるので、組織的な golang 習熟を目指すのであれば他に golang を触ってみたエンジニアの課題感は重要です。
セットアップは Circle CI の設定ファイルがそれに該当しますが、コンパクトなモジュールなりに設定手順がシンプルに収まりました、golang エコシステムが非常に簡便に利用できるというのも一因です。
今回はモジュール開発であるため、アプリケーションやサービスのようにクロスコンパイルしてバイナリをデプロイする、などのワークフローは体験できませんでした。
そこの領域にはまた、別の面白い課題があるんじゃないかな、と思っています。
構文解析対象としての NestedText
構文解析の題材としてなんとなく NestedText を採択しましたが、仕様が非常にシンプルだったのでちょうどよかったな、という感想です。
これが、見た目に騙されて YAML とか採択していたらエラいことになっていたでしょう。
NestedText は名前の通りネストを許容するフォーマットであるため、処理上も再帰構造を利用せざるを得ない感じです。
それが故に、ネスト構造が出現すると次の要素のパースをブロックしてしまいます。
幸いにも、YAML のようにネスト関係ではない要素同士での依存関係は起きないので、goroutine によるネスト単位での解析の並列化などを、今後の学習の題材として考えていきたいと思います。
(とりあえず子要素の パースを goroutine で回すようにしてみたら逆に速度が劣化しました、一筋縄では行かないようです)
まとめ
以上、とりとめもなく書いてきましたが、ざっとまとめたいと思います。
- 軽い気持ちでパーサー実装したら楽しかった
- マーシャルかっこいい
- 構文解析が初めてでも NestedText は解析できた
- やっぱり学びがあった
- zenn で真面目に書け
ここまでお付き合いいただきありがとうございました。
明日の記事も私が担当しており、まったく毛色の違ったテックブログ振り返りについて公開予定です。
また明日お会いしましょう、アリーヴェデルチ!
ドリコムでは一緒に働くメンバーを募集しています!
募集一覧はコチラを御覧ください!