
これはドリコム Advent Calendar 2016 3日目です。
クラウドの仕様にとらわれないデプロイを実現するために採用したStretcherとConsulについて
選択の経緯とその利用事例を紹介したいと思います。
自己紹介
社内ではsexyと呼ばれています。
珍妙なあだ名がついてしまった経緯については、いつかどこかで。
ソーシャルゲームの開発・運用やアプリ基盤開発を経て、今はインフラ部員です。
複数のクラウドを利用するためにそれらを抽象化したプロビジョニング環境を提供する開発プロジェクトでリーダーをやりました。
背景
弊社はAWSを中心にクラウドサービスを利用してきましたが、他のクラウドを並用したい思惑もあって
AWS前提での運用を見直して、機能差分は自社開発で補うことによって、クラウドを選ばない運用を
する試みに着手していました。
そのときに目指していたのがポイントが以下になります。
- 環境毎にバラバラになっているプロビジョニングのフローやツールの統一化
- CentOS7へ収束させていく
- オートスケーリング機能の実現
3つめのオートスケーリング機能の実現には、オートデプロイを実現する必要がありました。
オートデプロイへの道
オートスケーリングで増えたサーバがサービスに参加するためには、増えたサーバ自身のタイミングで
最新のソースでデプロイするしかありません。
ローカルマシンから対象サーバを選んでデプロイするpush型から、リモートサーバ自身が非同期に
デプロイするpull型へ移行していく必要があります。
capistrano運用の成熟
弊社で利用しているcapistranoをベースとしたgem群は、今までの様々な運用シーンから改修を重ねて
成熟しています(新規追加のみで100近いtaskがあります)
これらをpull型デプロイ用に作り直して一息に置き換えることは現実的でないように思えました。
そのため、今のcapistranoを内包して利用できる、または、新しいdeployツールと並用できるカタチを
目指していくことになります。
pull型デプロイの模索
オートスケーリングで増えたサーバがgitリポジトリから最新のmasterを取得してローカルにデプロイをすることで、既存のcapistranoのままでもオートデプロイ自体は実現できます。
ただし、数十台の不特定多数のサーバから一斉にgit pullされる状態は避けたくもありました。
他、今までの運用からAWS用にpull型デプロイに対応したcapistrano実装も既にあったのですが
運用するクラウドが増えるにあたり、都度そのクラウドのAPI仕様に則った拡張が必要となるため
そのやり方自体を見送りました。
capistrano資産を引き継ぎつつ、capistrano側にクラウド抽象化レイヤーを持たせることをやめることができるpull型デプロイツール、これらの条件で検討を重ねた結果、最終的に選択されたのは・・・
Stretcherとcapistrano-stretcherという組み合わせです。
ツールの簡単な説明
Stretcher
fujiwara氏が提供しているデプロイツールです。
後述するConsulのイベントをトリガーにして、あらかじめクラウドストレージにアップロードした
ソースとマニフェストをリモートサーバにダウンロードして、マニフェストに沿った振るまいをします。
https://github.com/fujiwara/stretcher
capistrano-stretcher
GMO Pepabo社が提供しているcapistrano関連gemライブラリです。
Stretcherをcapistranoから利用できるようになっています。
少ない実装で既存のcapistrano資産をそのまま流用できそうだったところが決め手です。
https://github.com/pepabo/capistrano-stretcher
Consul
HashiCorp社が提供しているサービス管理ツールです。Stretcherが依存しています。
consul-serverとconsul-clientでクラスタリングし、イベント発行や状態監視
また、KVS的な利用も可能です。
今回の事例では、実質、クラウドの抽象化レイヤーも担っています。
構成
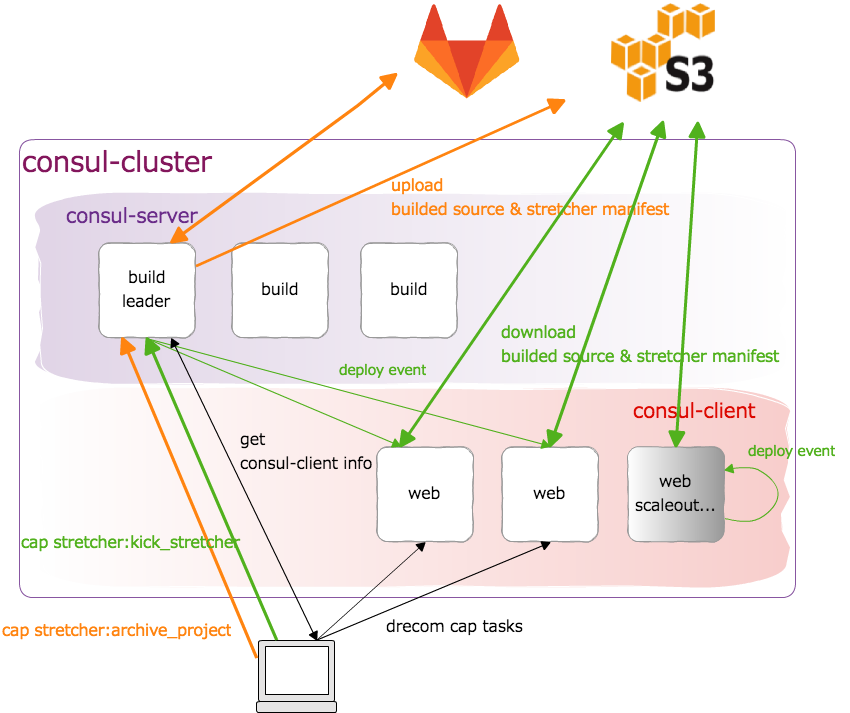
build-server
アプリのソースをビルドしてクラウドストレージにアップロードするサーバです。
capistrano-stretcherからcap stretcher:archive_projectを実行した際に
git clone、bundle install, rake assets:precompile…
もろもろビルドした上で、固めたものをS3にアップロードしています。
consul-cluster
consul-server
オートスケーリング機能で増減するアプリサーバ(consul-client)を管理するサーバです。
サーバの検出とクラスタで用いるグローバルな情報の保持、デプロイイベントの発行が主だった役割と
なっています。build-serverに同居しています。
capistranoからconsul-serverとつながれば機能する、というのがデプロイレベルでのクラウド抽象化の核です。
consul-client(web,job)
世情で増えたり減ったりするアプリのサーバ群です。
スケールアウトの際は下記のフローで追加されます。
- アプリ固有イメージのインスタンス化
- クラウドからサーバタグ情報などを取得してitamae
- consul-clusterに参加
- consulによってデプロイイベントを自分自身のnodeを対象に発行
- stretcherによるデプロイ
Amazon S3
buid-serverで固めたソースとマニフェストを置くクラウドストレージです。
実装
build & consul-server
build-serverとしての実装はほとんどありません。
cap stretcher:archive_projectを実行する上で必要なものを追加していきました。
弊社では、gitとS3を利用するためにデプロイ専用ユーザを作り
ユーザのssh-private-keyやcredentialsは、ConsulのKVSへ登録しています。
consul-serverは下記のようなオプションでエージェントを起動しています。
consul agent -server -bootstrap-expect 3 -retry-join=consul-server-01 -retry-join=consul-server-02 -retry-join=consul-server-03
consul-client
下記を全てitamaeによって用意しています。
- consulをsystemdに登録、起動
- consul watchによるデプロイイベントの待受けをsystemdに登録、起動
- デプロイ時に必要になるcredentialsやstretcherマニフェストの在り処をConsulKVSから取得して、セットアップ
- 自分自身を対象にしたデプロイイベント発火スクリプトをsystemdに登録、起動
systemdのサービスとして登録している理由としては、起動順序に依存関係や条件を持たせやすく
時系列的にログも追いやすいことがあげられます。
事故防止やリカバリのためにもなるべくそうしています。
capistrano-stretcher
基本的にはbuild-serverとconsul-clusterを構築した後ならば、deploy.rbにそれらを指定してあげる程度でローカルマシンからstretcherによるデプロイが可能となります。
しかし、このままでは従来のcapistrano資産は利用できません。
サーバをcapistranoのDSLで定義していないためです。
従来のように一つ一つ定義してあげることで機能はしますが、煩雑ですし、リアルタイムで増減する
サーバに対応できません。
結論として、Consulによって管理しているサーバの情報を取得してcapコマンド実行時に
動的にDSLで定義するtaskを作りました。
namespace :consul do
namespace :cluster do
desc "Get alive consul-cluster node & role infomation"
task :node_table do
on roles(:consul) do
stg = fetch(:stage).to_s
roles = fetch(:consul_cluster_roles, %w(all))
pattern = /#hostnameでmatchさせる正規表現/
base_query = %( map({key: .Node, value: {ip: .ServiceAddress, roles: .ServiceTags}}) )
select_query = %( map(select(.key | test("#{pattern}")) | select(.value.roles[] | test("#{roles.join('|')}"))) )
query = %( #{base_query} | #{select_query} | from_entries )
node_table = capture("curl -s http://localhost:8500/v1/catalog/service/role | jq -r '#{query}'")
info node_table
set :consul_cluster_node_table, JSON.parse(node_table)
end
end
desc "Load consul-cluster & Call 'server' of Capistrano DSL"
task :load do
next if fetch(:stage).nil?
invoke "drecom:stretcher:consul:cluster:node_table"
node_table = fetch(:consul_cluster_node_table, nil)
node_table.values.each do |v|
roles = v["roles"] & fetch(:consul_cluster_roles, [])
server v["ip"], roles: roles unless roles.empty?
end
end
end
end
そこそこ力技です。
consul:cluster:loadをdeploy/stage.rbでinvokeするだけで、capistrano側で生きてるサーバを
全て認識してHOSTやROLESで対象のサーバにtaskを実行することが可能になりました。
実装を見ていただくと分かるとおり、Consulから取得できたサーバ情報のjsonをhostnameで
マッチングさせて、ipとroleを抽出しています。
hostnameの生成に厳格なルールを作ったことと、サーバのロールをクラウドだけでなく
Consulでも管理していることによって実現しています。
おわりに
以上、絶賛過渡期に入っている弊社のデプロイ前線をお伝えしました。
まとめると、pull型のデプロイを導入しつつ、ローカルからリモートへダイレクトにcapistranoのtaskを実行可能な状態に残しているといったことになります。
capistranoのdeploy/stage.rbの記述次第でpush型もpull型も選択可能なため
これはこれで便利かなと思っている次第です。
さらに掘り下げた内容や運用知見などについては、いずれお話できればと思います。
クラウド抽象化のプロジェクトに関わった他のメンバーの記事です。