
■本記事についてのサマリ
▽内容
モバイルアクションゲームにおいて、機械学習と影響マップを活用した
ゲームAIの構築・開発手法についての説明
※下記内容にてドリコムより特許取得済みの手法となります。
発明名称:
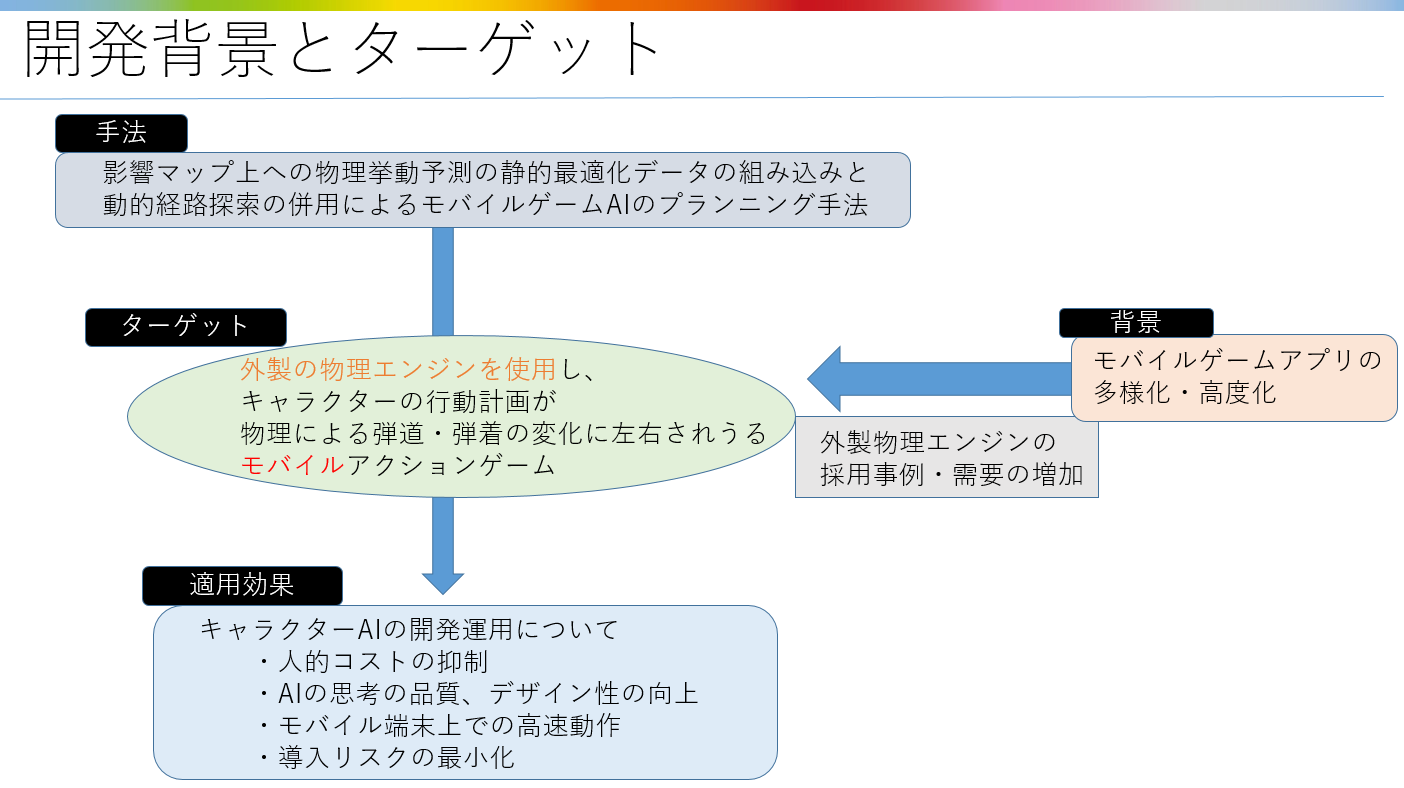
影響マップ上への物理挙動予測の静的最適化データの組み込みと
動的経路探索の併用によるモバイルゲームAIのプランニング手法
種別 :情報処理装置、情報処理方法、プログラム、ならびに、端末
登録番号:6258552
登録日 :平成29年12月15日
▽読者が得られる知見
・モバイルアクションゲームのAI開発における問題と、解決のための発想のアプローチ例
■アジェンダ
はじめに
1.解決手法の概要
2.外製の 物理エンジンを使用するにあたっての問題点
3.既存手法による解決のアプローチと課題
4.本手法による解決のアプローチ
5.導入のメリット
さいごに
■はじめに
みなさん、はじめまして! ドリコム開発ディレクターの佐藤といいます。
記事の本題に先駆けて、少しだけ自己紹介をさせてください。今でこそ企画職ではありますが、
私、元々はゲームAIを軸足にしたゲームエンジニア兼リサーチャーでして、
これまでコンシューマからスマートフォンゲームまで、研究部門に片足を突っ込みつつ、
現場でのキャラクターAIの構築とデザインに携わってきました。
本記事でもドリコムでのゲームAI開発の取り組みの一環について、
御案内させて頂ければと思います。
挑戦心をくすぐる強大なボス敵、愛嬌一杯のマスコットモンスター、
冒険を共にする頼れるパートナー…ゲームに登場するキャラクター達は本当に魅力的ですよね。
近年では、AR・VR、スマートフォンデバイスの高性能化に伴い、ゲームとキャラクター表現の可能性も大きく広がってきました。ドリコムでも、ユーザーの皆様により楽しい時間を届けるべく、新しい時代に向けた様々な発明の取り組み、導入検証を行っています。
本記事では、これらの取り組みの中から生まれた
モバイルアクションゲーム用のキャラクターAIの開発手法について御紹介したいと思います。
1. 開発手法の概要
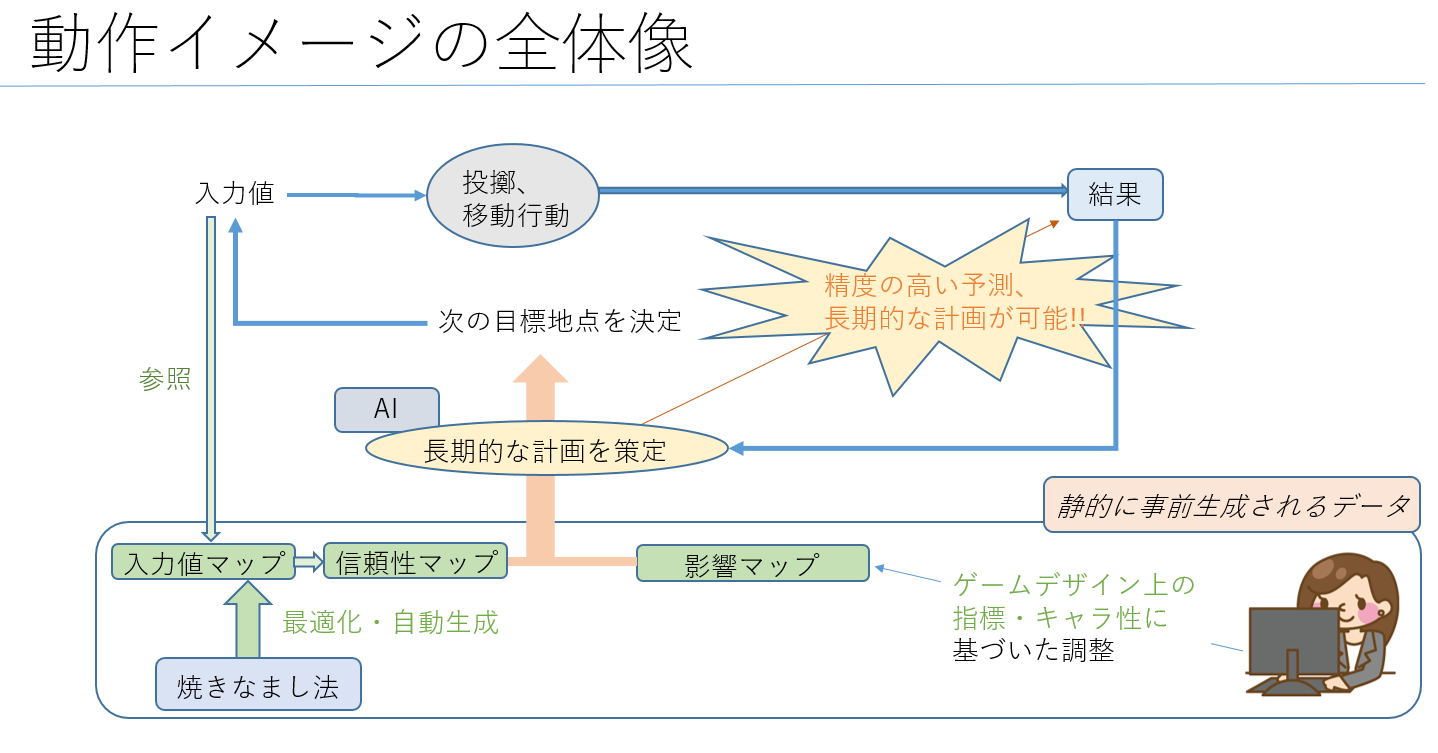
本手法は下記の4つのデータマップと動的なグラフ探索を併用することで、
弾道の予測が必要となるような物理を使用したモバイルアクションゲームにおいて、
既成手法ではモバイル端末上での表現が難しかった環境情報を加味したキャラクターの思考制御を、
高速かつ低コストで実現することを目的としたものです。
・機械学習により静的に算出した地点間の最適解の集合
・機械学習により静的に算出した地点間の成功の確度の集合
・静的に作成された効用値の集合(影響マップ)
・動的に作成された効用値の集合(影響マップ)
これらを動的に掛け合わせたマップ上で動的なグラフ探索によるプランニングを行うことで、
効用ベースでのAI制御の組み込みを実現しつつ、ランタイムでの計算コストを低減し、
開発コストの抑制と高速稼働、ゲームデザイン上の表現力の向上を実現するものです。
昨今のモバイルコンテンツの多様化・複雑化に伴い、
Unityなどの外製のフレームワークや物理エンジンを採用する事例も増えてきました。
本手法においては、外製の物理エンジンを活用した場合でも、
エンジン内部のロジックに依存することなく、
物理挙動を踏まえたキャラクターの思考の構築と開発が可能です。
2.外製の 物理エンジンを使用するにあたっての問題点
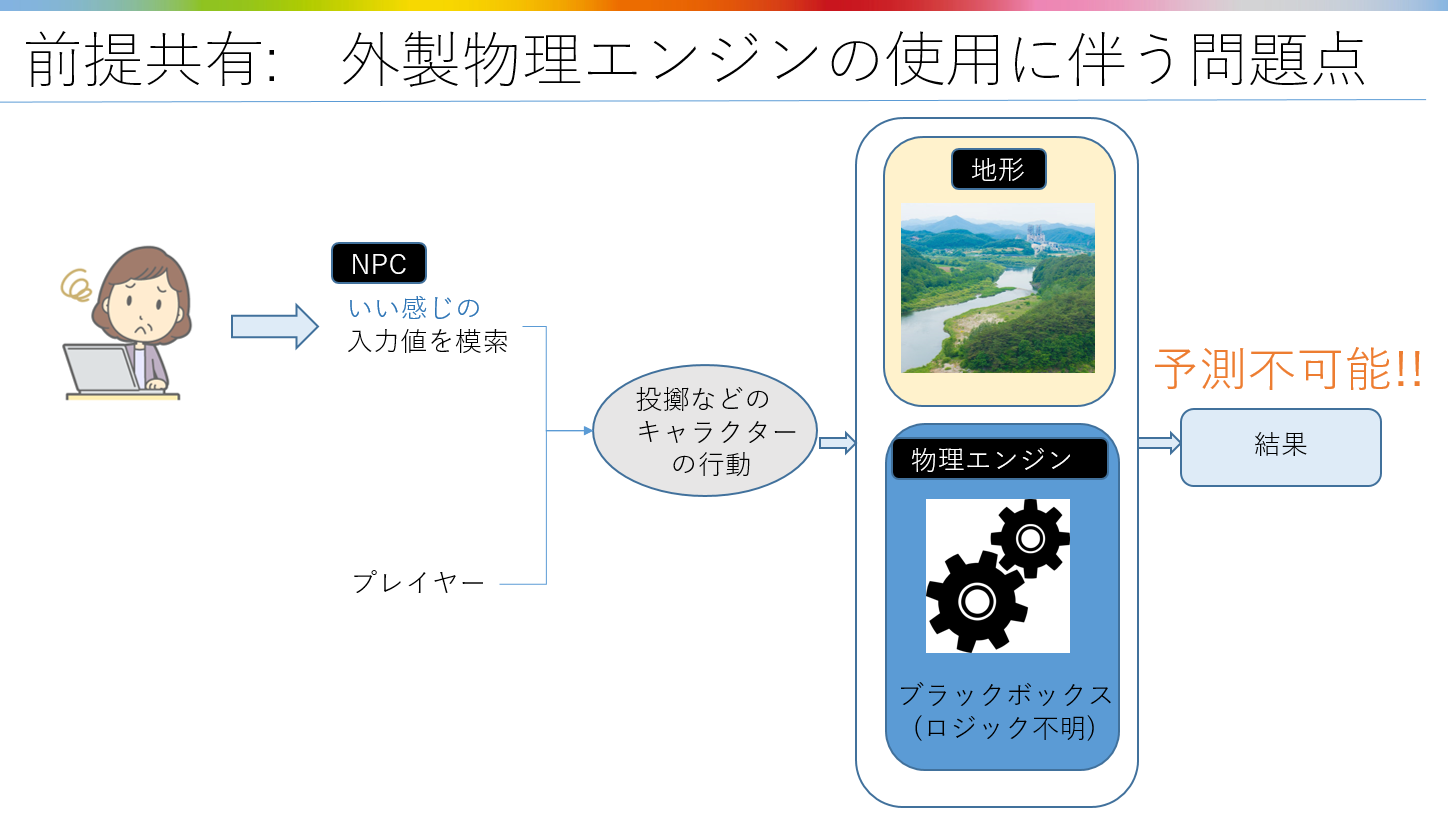
外製の物理エンジンを使用した開発で、
物理挙動を踏まえたキャラクターの思考を構築するにあたって、障害となるのが
『物理エンジンの内部ロジックがブラックボックス』である点です。
特定の地点を狙って、キャラクターを跳躍させたり、物体を投擲しようとした場合に、
どの程度の力加減でどこに狙いをつければ良いのか、
物理エンジンの内部ロジックが不明であるために入力値を結果から逆算することができません。
人間が肌感を頼りに入力値を調整しようにも、
ゲーム中の障害物に物体がぶつかれば弾道は変化しますから、
地形や環境を踏まえた汎用的な入力値を事前に人間が策定することは困難です。
■発生しうる問題
(1)入力パラメータの調整が人間の肌感頼り
➡結果が読めないため、調整困難。開発長期化に伴う人的コスト・人員のアサインコストの爆発
➡モバイルゲームの多くは、長期の運用を前提とするため、 AIの開発運用に伴うコストも肥大化
(2)環境情報 (風速、遮蔽、地形の起伏等)を考慮できない
➡イレギュラーに弱く、キャラクターが特定の地点から抜け出せなくなるなどの可能性がある
(3)長期的な行動計画をAIに立てさせることができない
➡物体の投擲を複数回繰り返して、遠方の目標点に到達させる場合などは、
投擲を繰り返すほど、予測結果に誤差が重なっていく。長期的な行動計画の策定は困難。
3.既存手法による解決のアプローチと課題
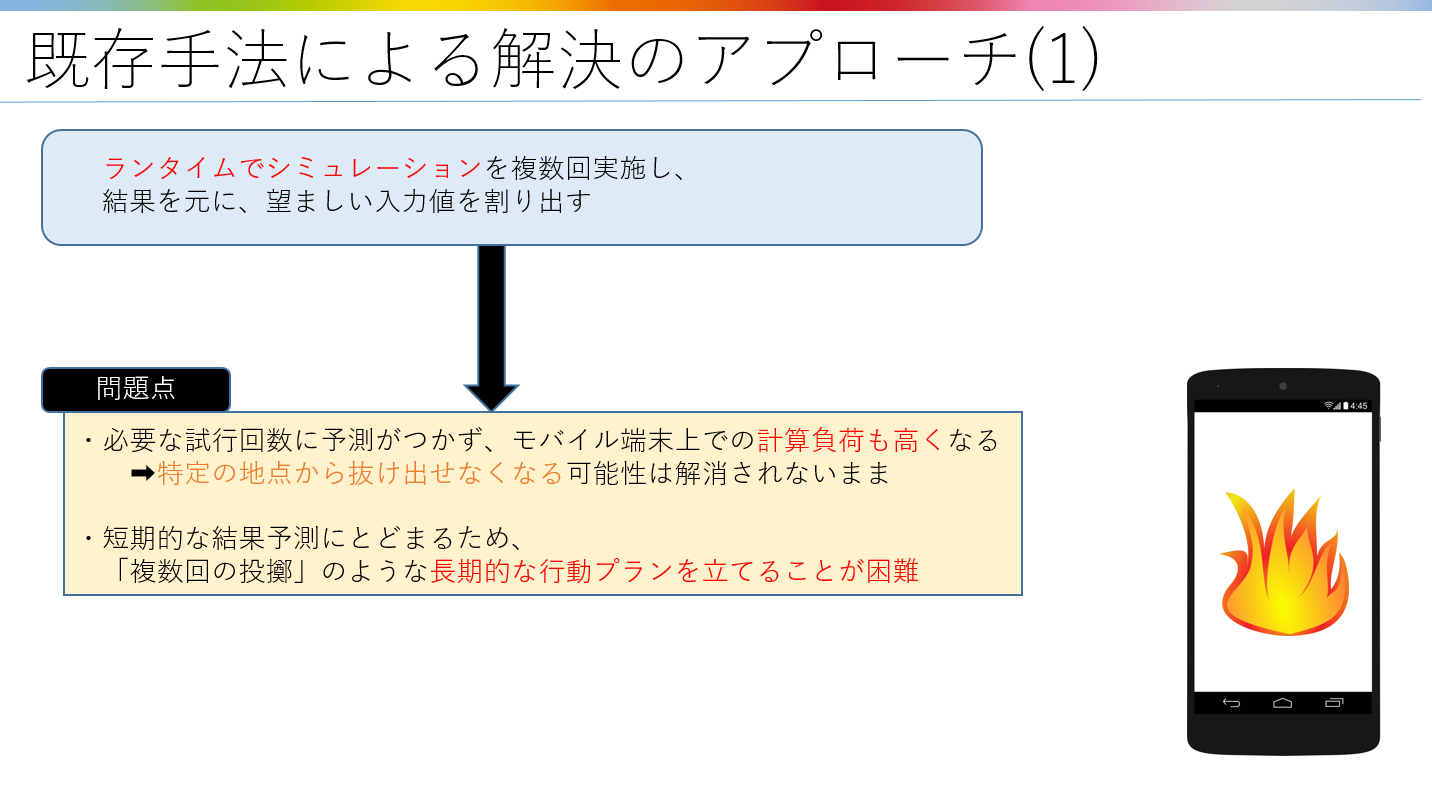
前述の問題に対して有効となるアプローチが、実際に弾道のシミュレーションを行って結果を算出し、
その結果に基づいて必要な入力値や計画を策定する、といった手法です。
ただし、物理エンジンを介したシミュレーションは、それなりに計算負荷がかかるため、
モバイル端末上でゲーム実行中にシミュレーションを繰り返すことは、あまり現実的ではありません。
ここで良く行われるのが、シミュレーションをゲームの動作中ではなく、
ゲームの外部で事前に行ってしまい、動作中はシミュレーションの
結果のみを参照するというアプローチです。
たとえば、事前に特定の弾道を導く入力値を複数算出しておき、
各入力値の補間により、望ましい弾道に近い入力値をもたらすという手法だとどうでしょうか?
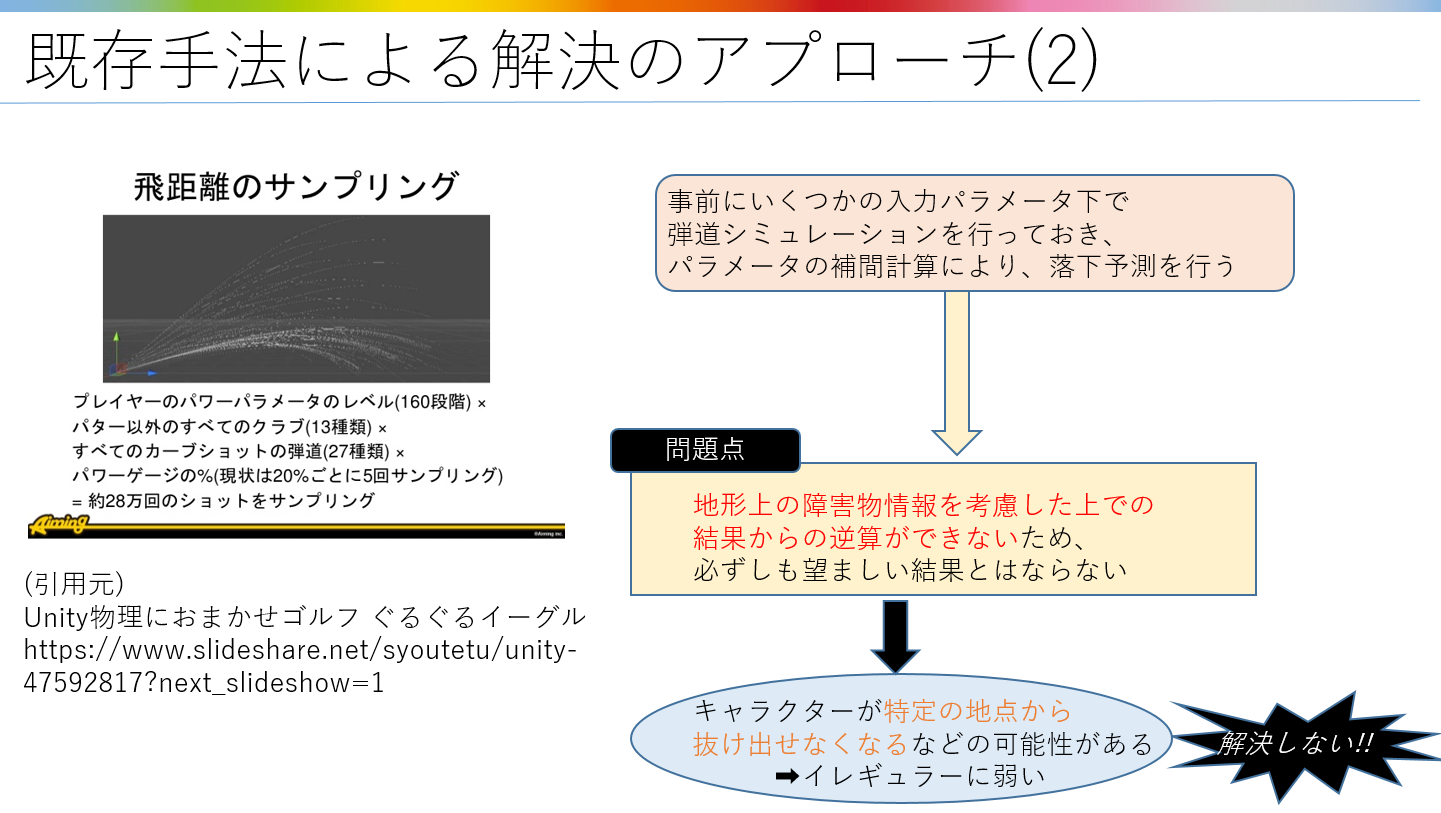
人間の手でパラメータ調整を行うよりも、ずっと調整負荷は軽くなりますが、
弾道上に障害物などがあると、結果は予測と違ったものになってしまいます。
短期的な行動予測の精度が期待できないため、
複数回の投擲を要する長期的な行動プランの策定も難しそうですね…
4.本手法による解決のアプローチ
ここまでの考察でAIの行動プランの策定のために、
環境情報まで考慮に含めた入力値の算出が必要なことがわかってきました。
本手法ではゲーム中の実際のマップ上で事前に機械学習を行い、
マップ個別に各地点間の最適な入力値を算出し、
下図のような形で保持することで上記の問題を解決します。
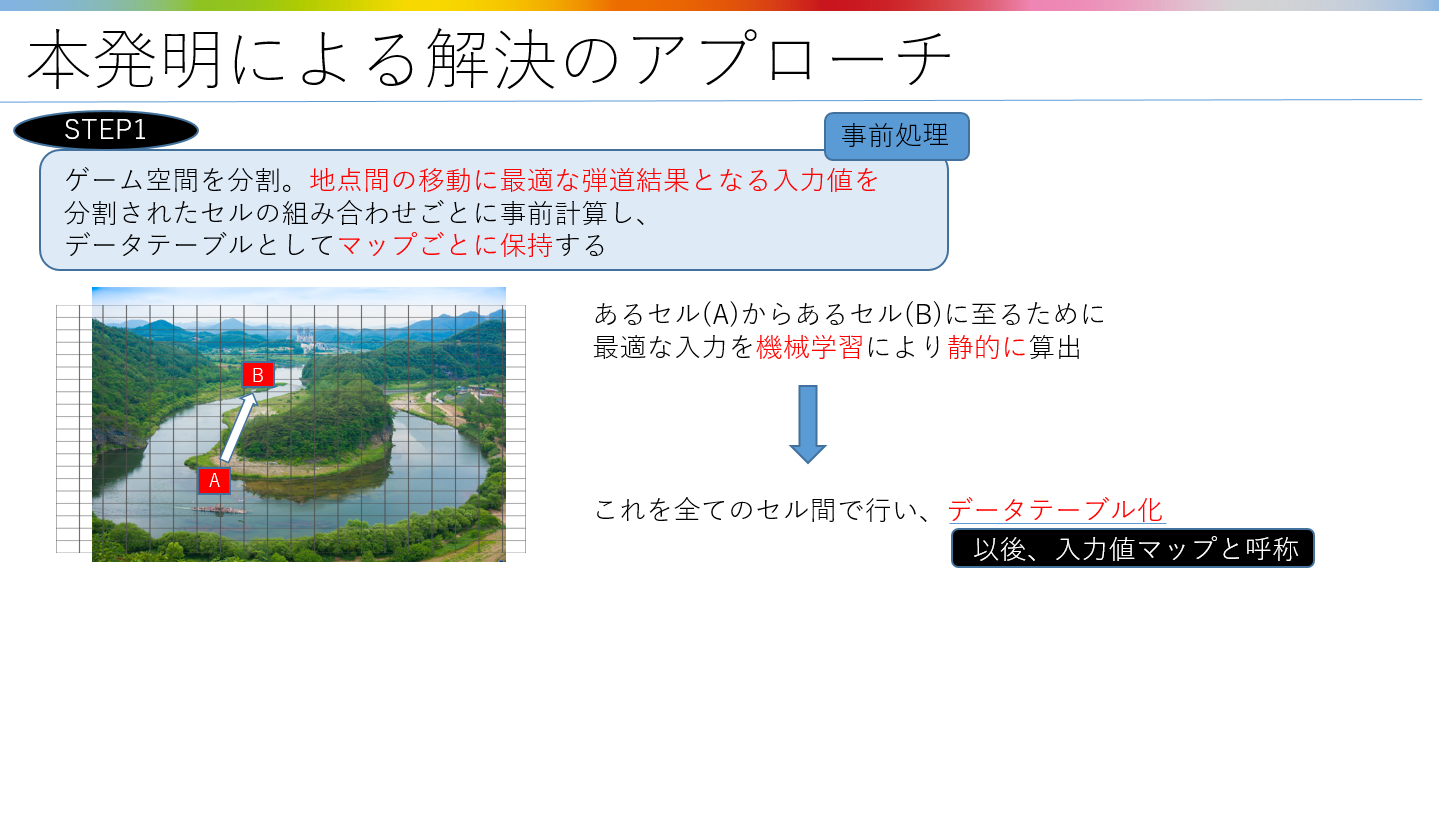
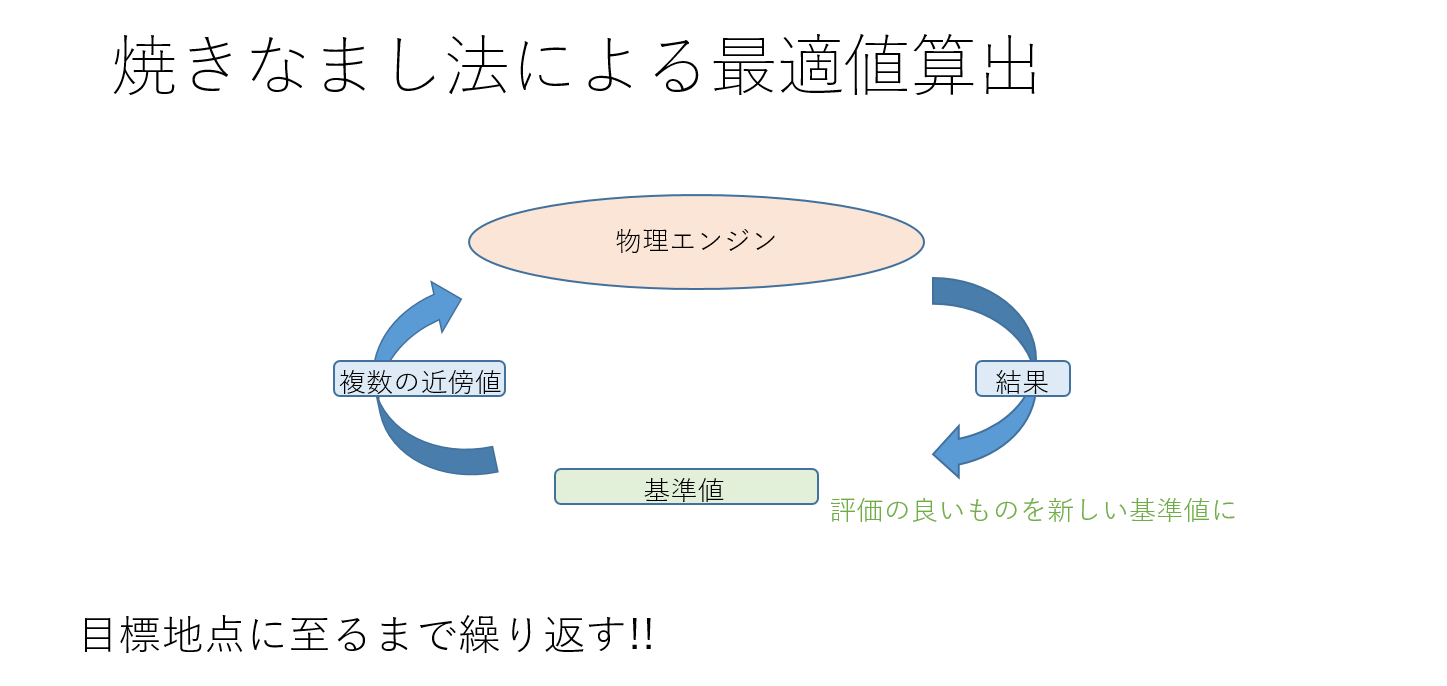
入力値の最適化のための学習手法は色々と考えられるのですが、
ここでは焼きなまし法を例にとります。
実装コストが極めて低いので、検証も容易ですし、下記のようなメリットも望めます。
■メリット
・1回のイテレーション負荷が低い
・単純な投擲や跳躍行動の場合、入力値と結果に線形的な相関が確立されやすいため、結果の収束が高速
・複数ゲームタイトルでの採用実績がある学習手法であり、開発現場への導入に対する心理障壁が低い
・局所回に陥りにくく、高精度の結果が期待できる
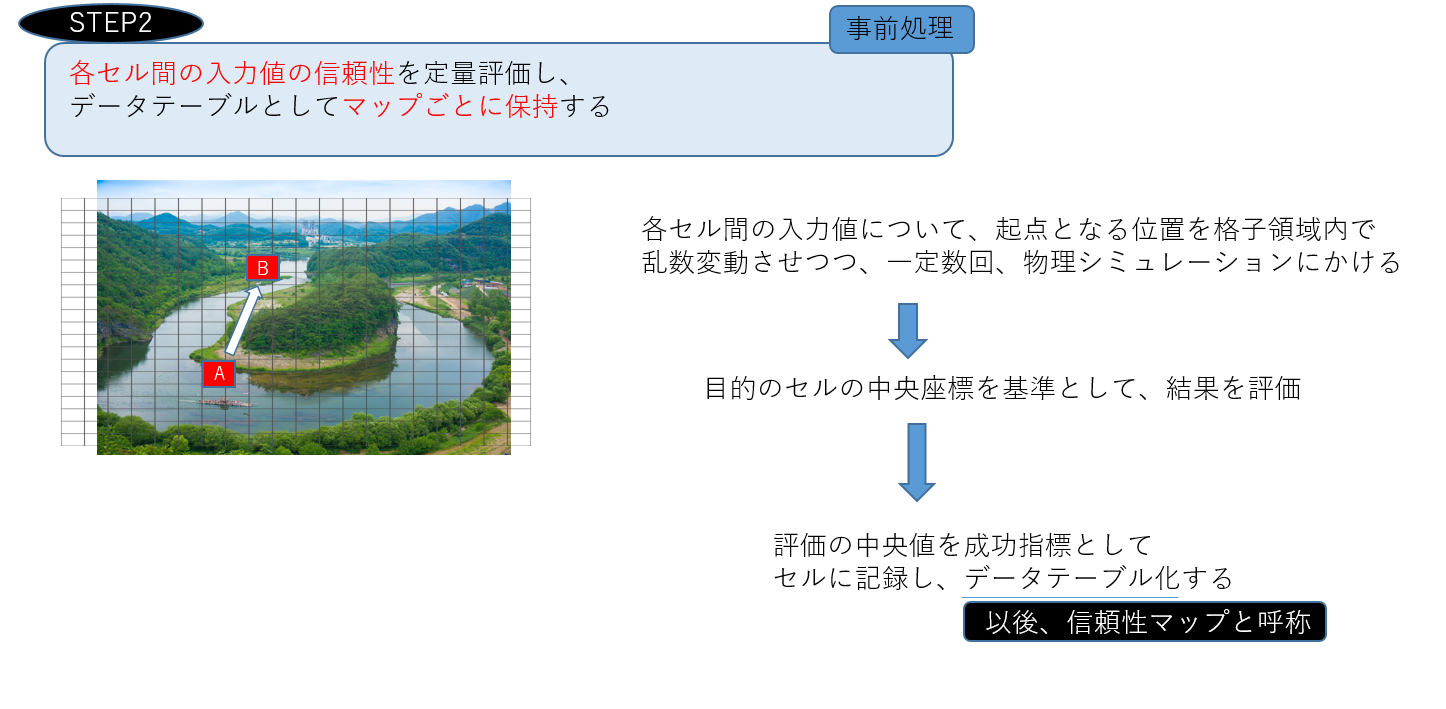
算出した入力値ですが、分割したセルの粒度や学習の過程によって、
値の信頼性にある程度ばらつきが出てくるため、これを考慮するために入力値とは別個に
各入力値の信頼性をデータテーブル化して保持します。
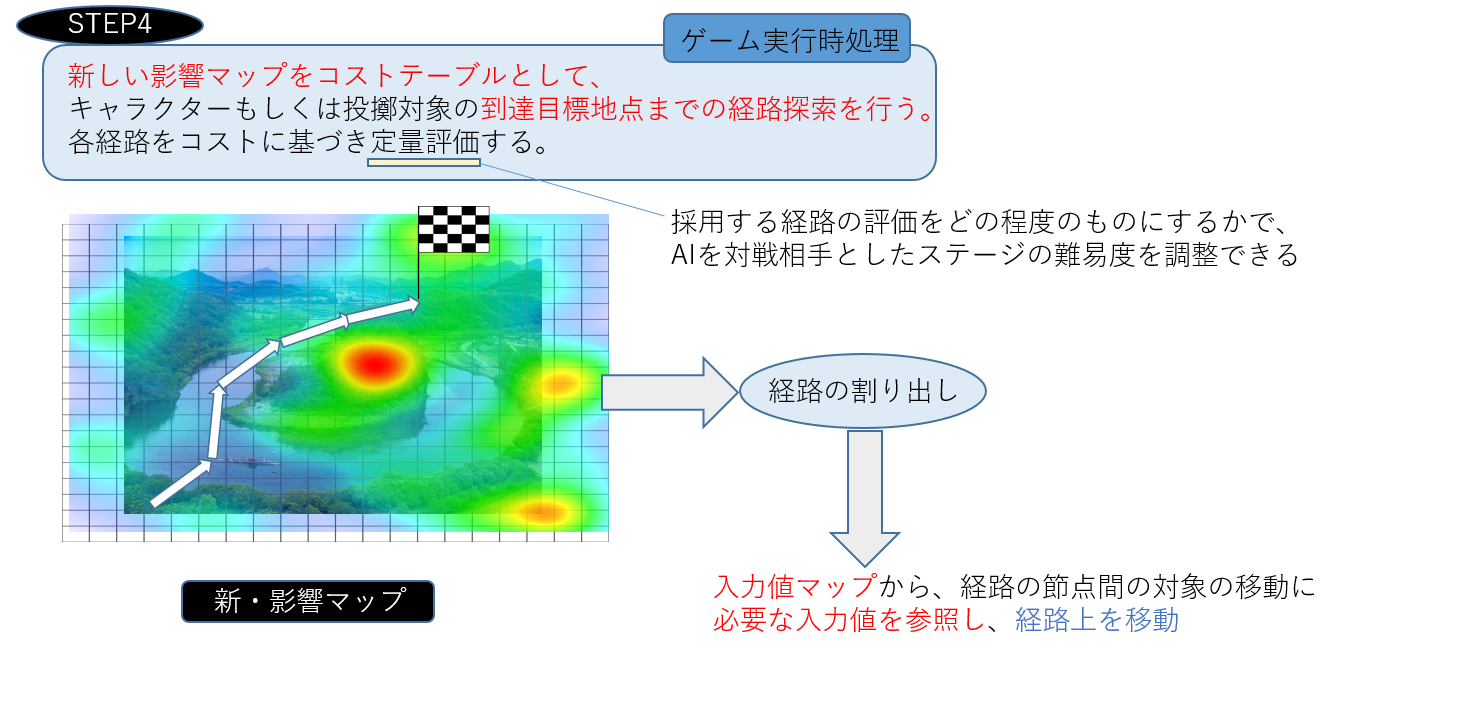
マップの環境情報を踏まえた各地点間の入力値が取れたので、これらを活用して
特定の地点間を跳躍移動したり、目標点に物体を投げ込んだり、といった行動を取らせることは容易になりました。
信頼性の値を参照すれば、より確実な経路をAIに判断させた上で、
跳躍・投擲を行わせることも可能です。
ただし、ゲーム中のキャラクターにとって、どの地点に位置取りしていくべきかは
確実性によってのみ評価されるわけではありません。
キャラクターの性格や、敵性プレイヤーからの距離、高所などの戦略上の優位性など
ゲーム中に変動する様々な要素が関わってきます。これらの要素は各指標ごとに
影響マップを作成し、信頼性マップに掛け合わせることで、加味します。
※影響マップは、AIの知識表現における古典的な手法の一つです。
ある一定の指標に基づいた各地点の評価を環境上にレイヤリングしたもので、
影響マップ同士を指標の重要性を係数として掛け合わせることで、
環境情報を加味した複雑な判断を効用ベースで高速に行うための判断指標として活用できます。
影響マップについては、以前Cygames様にて執筆させて頂いた
下記の記事で詳しく紹介しています。御参考ください。
(参考)Cygames Enginner’s Blog 知識表現と影響マップ
http://tech.cygames.co.jp/archives/2272/
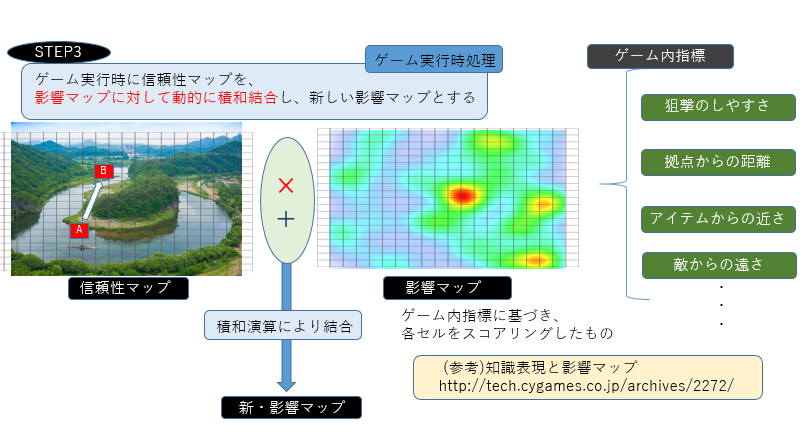
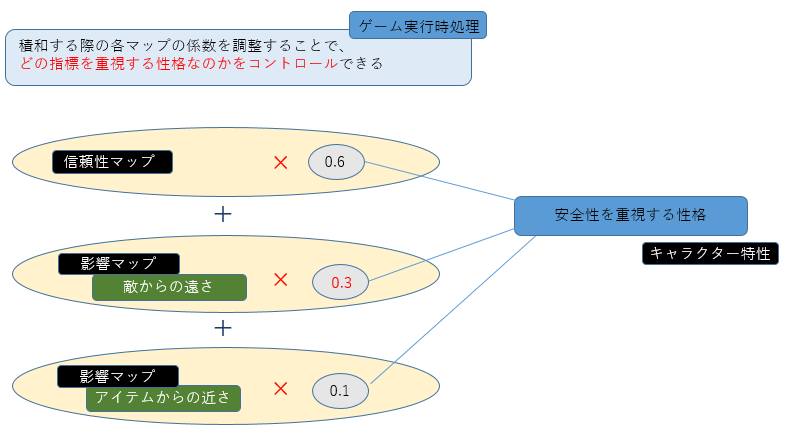
積和結合の際に信頼性マップの評価係数を大きくすれば、確実な経路を重視する慎重なキャラクターを、敵性プレイヤーからの距離の評価係数を大きくすれば、プレイヤーを避けて回る臆病なキャラクターを演出できます。
どの指標をどれだけ重視するかをパラメータとして弄れるようにしておけば、
ステージやゲームコンセプトに応じたキャラクターの個性を
最低限の設定で調整していくことが出来そうですね。
5.導入のメリット
本手法によって何が実現されるのかをまとめてみましょう。



着眼するべきは、 AIの行動のみならず、信頼性マップと影響マップ上の各地点の評価点を元に
ユーザーのプレイングを定量評価することができる点です。
例えば、プレイヤーのファインプレーに対してAIが賞賛を送ったり、
プレイヤーのプレイングのレベルに応じて、AIに手加減をさせたりといったことが可能になります。
プレイヤーのプレイングの定量評価を活用したゲームAIのデザインもまた
面白い題材ですので、こちらも別の機会に考え方を御紹介させて頂ければと思います。
さいごに
いかがでしたでしょうか。ゲームのAIはちょっとした工夫や発想の転換で、
様々な表現が可能になる分野です。本記事が、より面白いゲーム体験を形作るための
知見共有の機会の一助となれば幸いです。ここまで読んで頂いて、ありがとうございました。