
はじめに
こんにちは、enzaプラットフォーム事業本部でエンジニアをやっている安藤です。運用しているプロダクトの本番環境をAmazon EC2からAmazon EKSに移行する日が来まして、良い機会なのでこれまでやってきた対応をまとめてみました。 と言っても、EKS周りのことは特に言及しません。
タイトルの通り、Railsアプリケーションをコンテナ化してKubernetes上で動かすための対応について書いています。
DockerやKubernetesの仕組みなどの説明は端折っているので、ご了承ください。 Kubernetesが普及して久しいですが、「運用中のサービスを移行したいけど、結構大変だな…」というプロダクトも多いのでは無いかと思います。
この記事が、そういったプロダクトの移行作業の助けになれば、嬉しい限りです。
移行前のシステム
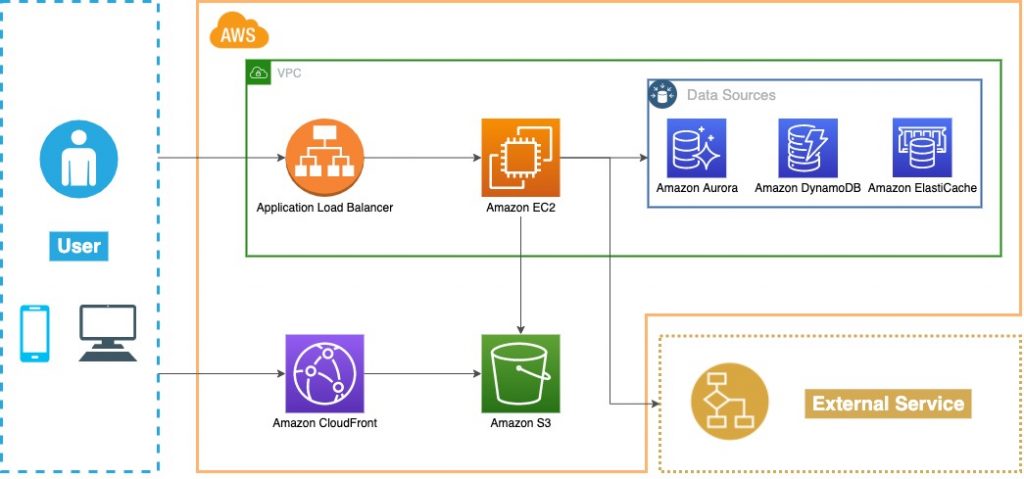
まぁ、よくある構成ですよね。
抱えていた課題点
わりと長く運用しているサービスなので色々抱えていた課題はあるのですが、今回の載せ替えのモチベーションになったのはこの辺りです。- スケールイン・アウト等のオペレーションコストがかかる
- 手順や注意点が多く、属人化しやすい(触ってた人が辞めたらアウト)
- できる人がなかなか増えない
- 作業が面倒くさい
- 言語やライブラリのアップデートが大変
- マシンイメージ作り直してインスタンスを全部取り替えたり
- プロビジョニングツール流さないといけなかったり
- うむ、面倒くさい
課題に対するアクション
行ったことは大きく分けてこの2点。- Railsアプリをコンテナ化する
- Rubyのバージョンアップやライブラリの追加をするときはDockerfileを更新するだけで済む
- Kubernetes上で動かす
- インフラがPod / ReplicaSet / Deployment / Service等のリソースに抽象化される
- インフラ構成をマニフェストファイルで一元的に管理できる
- コード化されるため誰でも読めるし書ける(Infrastructure as Code)
移行後のシステム
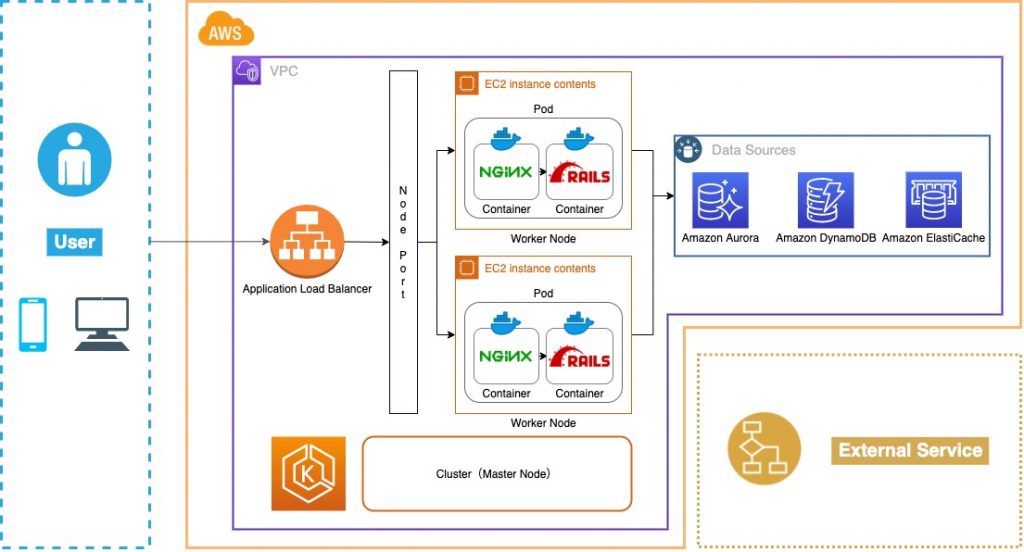
レッツコンテナオーケストレーション。
Railsアプリをコンテナ化する
コンテナで動くようにしていなかったので、以下の対応を実施。- Dockerfileを書く
- コンフィグを整理する
1. Dockerfileを書く
まずは構成をどうするかですが、移行前から変える理由もなかったので、- Rails(Unicorn)+ Nginxの構成でコンテナはそれぞれ分ける
Nginx
ディレクトリ構成はこう。
- docker
- nginx
- templates
- nginx.conf.tmpl
- (設定系のファイルが諸々)
- Dockerfile
nginx.confの設定値を変えたかったので、Entrykitを使ってテンプレートのレンダリングを行っています。そういった事情がないのであれば、公式イメージを使えばいいかなと思います。
ARG NGINX_VERSION=1.15.12
FROM nginx:${NGINX_VERSION}-alpine
ARG ENTRYKIT_VERSION=0.4.0
RUN apk add --no-cache openssl && \
wget https://github.com/progrium/entrykit/releases/download/v${ENTRYKIT_VERSION}/entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz && \
tar -xvzf entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz && \
rm entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz && \
mv entrykit /bin/entrykit && \
chmod +x /bin/entrykit && \
entrykit --symlink && \
rm -rf /etc/nginx/nginx.conf.default /etc/nginx/conf.d/*
WORKDIR /etc/nginx
COPY templates/ /etc/nginx/
EXPOSE 80
ENTRYPOINT [ \
"render", "/etc/nginx/nginx.conf", "--", \
"/usr/sbin/nginx", "-c", "/etc/nginx/nginx.conf" \
]
Rails
何も考えずにDockerfileを書いてビルドすると、イメージサイズが1GB超えてて吐き気を催したりします。軽量化しないとビルドやらプッシュやらに時間がかかって仕方ないので工夫必須。 よく書かれている対応方法のまんまですが、手を打ったのはこの2点。
- Alpine LinuxベースのRubyコンテナを使う
- Multi-stage buildsを使う
1. Alpine LinuxベースのRubyコンテナを使う
要するに、ベースとなるコンテナを軽量なものにしました。Linuxとかの操作に慣れていると「え、ログインシェルがash?なにそれ」という感じになりますが、使い方さえ分かれば気にならないし、Kubernetes上で動かすようになったらコンテナにログインする機会自体が少ないので、特に支障はなかったです。
2. Multi-stage buildsを使う
bundle installはビルドステージで行い、最終的なステージには必要な成果物だけを持っていくようにして、サイズを軽くしました。Multi-stage buildsを使わなくても、ビルド時に生まれた不要なファイルを手動で削除していけば軽くできるのですが、使ったほうがDockerfileもスッキリするし良いかなと思います。
できたDockerfileはこちら
# syntax = docker/dockerfile:experimental
# BuildKitを有効にしている
# ステージ共通で使うargs
ARG RUBY_VERSION=2.5.8
ARG ALPINE_VERSION=3.12
ARG BUNDLER_VERSION=1.17.3
ARG BASE_PACKAGES="busybox-suid git openssh shadow tzdata logrotate"
FROM ruby:${RUBY_VERSION}-alpine${ALPINE_VERSION} as builder
# Multistage buildsの場合はステージ内で再定義が必要
ARG BUNDLER_VERSION
ARG BUNDLE_OPTIONS
ARG BASE_PACKAGES
ARG BUILD_PACKAGES="alpine-sdk build-base linux-headers mariadb-dev"
ARG BUNDLE_OPTIONS="--jobs 4 --local --quiet --deployment --binstubs bin --without development test deploy"
COPY Gemfile* /
COPY vendor/cache /vendor/cache
RUN --mount=type=secret,id=ssh,target=/root/.ssh/id_rsa \
apk add --no-cache ${BASE_PACKAGES} ${BUILD_PACKAGES} && \
chmod 700 /root/.ssh && \
ssh-keyscan -H github.com >> /root/.ssh/known_hosts && \
gem install bundler --version ${BUNDLER_VERSION} --no-document && \
bundle config set path /vendor/bundle && \
bundle install ${BUNDLE_OPTIONS} && \
find /vendor/bundle/ruby -path "*/gems/*/ext/*/Makefile" -exec dirname {} \; | xargs -n1 -I{} make -C {} clean
FROM ruby:${RUBY_VERSION}-alpine${ALPINE_VERSION}
ARG BUNDLER_VERSION
ARG BASE_PACKAGES
ARG RUN_PACKAGES="execline mariadb-client-libs openrc"
ARG APP_ROOT=/app
ARG APP_PORT=3000
ARG TIME_ZONE=Asia/Tokyo
# Rubyの公式イメージの設定を上書きする
ENV BUNDLE_APP_CONFIG ${APP_ROOT}/.bundle
WORKDIR ${APP_ROOT}
# 成果物だけをビルドステージから持ってくる
COPY --from=builder /vendor/bundle ${APP_ROOT}/vendor/bundle
COPY --from=builder /usr/local/bundle ${BUNDLE_APP_CONFIG}
COPY . ${APP_ROOT}
RUN apk add --no-cache ${BASE_PACKAGES} ${RUN_PACKAGES} && \
cp /usr/share/zoneinfo/${TIME_ZONE} /etc/localtime && \
gem install bundler --version ${BUNDLER_VERSION} --no-document && \
bundle config set path ${APP_ROOT}/vendor/bundle
# UnicornのSocketファイルをtmp配下に置くためNginxのコンテナからアクセスできるようにする
VOLUME ${APP_ROOT}/tmp
VOLUME ${APP_ROOT}/public
EXPOSE ${APP_PORT}
# プロセスの起動はシェルスクリプトにまとめている
ENTRYPOINT ["./entrypoint.sh"]
しかし、軽量化したとはいえビルド時間が4分くらいかかるのが気になりました。
そこでBuildKit先生の登場
「ビルド時間かかりすぎなんだけど…」そんなときは、Docker v18.09から正式な機能に昇格したBuildkit先生の力を借ります。 これを使うと、命令の並列実行であったり正確なキャッシュ判定であったりを、なんか上手いことやってくれます。(雑)
Dockerfileにちょっと記述を加えるだけなので、試して損はないと思います。 必要な作業は、
1. 環境変数の設定
export DOCKER_BUILDKIT=1
2. Dockerfileの先頭にShebang的な記述を追加
# syntax = docker/dockerfile:experimental
あとはビルドするだけ! 結果としては約60秒ほどビルドが速くなり、そしてビルド中の出力が格好良くなりましたw
Buildkit先生やりますね。
それと、Bundle install時にプライベートリポジトリのGemにアクセスするので、–secretというオプションも使っています。
Multi-stage buildsを使っていれば、機密情報がレイヤーに残ってしまう問題は気にしなくて良いと思いますが、まぁせっかくなので。 これでDockerfileのほうは完成です。
テスト
Dockerfileが完成したところで、動作検証を行います。諸々の対応が終わって「よしデプロイだ!」ってときに「・・・動かない」ってなるのは辛いですからね。。 Docker Composeを使って、パパッとローカルで動かせるようにします。
version: '3.1'
services:
rails:
image: rails:test # ローカルでビルドしたイメージを指定
container_name: api
build:
context: ./
volumes:
- app-log-data:/app/log
- public-data:/app/public
- tmp-data:/app/tmp
ports:
- 3000:3000
env_file:
- env_files/rails.env # 必要な環境変数を定義しておく
nginx:
image: nginx:test # ローカルでビルドしたイメージを指定
container_name: web
build:
context: docker/nginx
volumes:
- nginx-log-data:/var/log
- public-data:/app/public
- tmp-data:/app/tmp
ports:
- 80:80
depends_on:
- rails
env_file:
- env_files/nginx.env # 必要な環境変数を定義しておく
volumes:
app-log-data:
nginx-log-data:
public-data:
tmp-data:
docker-compose upしてコンテナを起動。あとはCurlコマンドなりで疎通確認ができればOKです。
2. コンフィグを整理する
続いてコンフィグ周りの整理となります。移行前のシステムでは、環境ごとのコンフィグの管理はGlobalというGemを使っていました。
config/deploy配下に環境ごとの設定を用意して、Capistranoを使ってデプロイを行なうため、同じく環境ごとの設定値を定義できるGlobalとの相性がとても良かったのです。
しかし、コンテナ化してKubernetes上で動かすとなるとシステム自体が変わるため、環境ごとの設定値を管理する仕組みを考え直す必要がありました。
コンフィグは大きく分けて、
- コンテナのビルド時に必要なもの
- DBの接続情報やNginx・Unicornの設定など
- アプリケーションの起動以降に必要なもの
- AWSリソースの接続情報やサービス特有の設定など
アプリケーションの起動以降に必要なものもConfigMap/Secretにしようかと思ったのですが、長く運用しているサービス故に相当な量のConfigがあり環境も多いため、さすがに管理が厳しいと判断。 アプリケーションの起動以降に必要な設定は、RailsのCustom-configurationを使用して管理することにしました。
Dry-configurableのようなGemを使うか迷いましたが、Railsの機能で十分かなと。 ふむ、これで方針は決まりました。
どう移行するか
移行時に困ったこととしては、既存のコードはありとあらゆるコンフィグがCapistrano+Globalありきの仕組みになっており、それを何とかする必要があるということでした。環境ごとにセットした変数をもとにテンプレートファイルをレンダリングして、生成したYAMLをデプロイするという仕組みなので、各環境のサーバーにしか完成されたYAMLファイルが存在しないのが厄介です。 もちろん、運用中のサービスなので「あ、DBの接続先間違えちゃった。えへへ」は許されません。
やり方は色々あるのでしょうが、何が何でも安心安全に移行していかねば。。 悶々と考えた結果、
- 正しい情報は、機械が生成した各環境のサーバーにあるYAMLファイル
- 間違える可能性があるのは、人間が新しく生成するCustom-configuration用のYAMLファイル
ということで、「1.」の値を正として「2.」の値を検証するRakeタスクを作成することにしました。
Rakeタスクを作る
と、タスクを作っていく前に、Custom-configurationの設定を書いていく必要があります。 (ついでにリファクタしたい気持ちをグッと堪えて)GlobalとCustom-configurationでコンフィグのKey/Valueは全く同じにして、Custom-configurationの設定はどこからも参照されないようにしておきます。 Custom-configurationでもGlobalのように機能ごとに設定ファイルを定義することができるので、
# config/example.yml
shared:
foo:
bar:
baz: 1
development:
foo:
bar:
qux: 2
production:
foo:
bar:
qux: 3
そして
application.rbで、
# config/application.rb
module MyApp
class Application < Rails::Application
config.x.example = config_for(:example)
end
end
# development environment
Rails.application.x.example[:foo][:bar] #=> { baz: 1, qux: 2 }
ふむ、良さそう。 しかしここで、Globalを使っていたが故に、とある問題にぶつかってしまいました。
そう…Globalは、
Global.example.foo.bar #=> { baz: 1, qux: 2 }
「僕らにはHashieがあるぜ。ふへへ」と余裕綽々で調整してみたところ、なぜかうまく動かず。 「そんな馬鹿な…なぜだ…?」と焦りを隠しきれないまま調べていたところ、コンフィグ内の一部のKeyがHashの予約語に被っており使えないことが判明しまして。(確か
defaultというKey)
今回は人間を信じないという方針で進行しており、手動での対応は避けたい。ということで思いついた苦肉の策がこちら。
# config/application.rb
module MyApp
class Application < Rails::Application
# コンフィグ内のNestされたHashにもドットでアクセスできるようにする
# HashではなくOpenStructを使っているのは、コンフィグのKeyがdefaultといったHashの予約語を使ってしまっているため
def define_nested_custom_config(config_hash)
config_hash.each_with_object(OpenStruct.new) do |(k, v), s|
if v.is_a?(Hash)
v = define_nested_custom_config(v)
end
s.send("#{k}=", v)
end
end
Pathname.glob(Rails.root.join("config", "custom", "*.yml")) do |f|
k = f.basename(".*").to_s
h = config_for(f).deep_symbolize_keys
custom = define_nested_custom_config(h)
config.x.send("#{k}=", custom)
end
end
end
うーん、移行時の安全確保のためとはいえ、なかなか辛い実装になってしまいましたね…。
今思えば、もう少し他に使えるGemがないか調査を行っても良かったかもしれません。 しかし、これでようやく準備は整いました!
あとは検証用のRakeタスクを作成すれば完成です。
task :check_custom_config => :environment do
Global.configuration.to_hash.keys.each do |key|
custom_config_hash = Rails.configuration.x.send(key)
global_config_hash = Global.send(key).to_hash.deep_symbolize_keys
next if custom_config_hash == global_config_hash
puts "Not match config! key:#{key}"
end
end
これを各環境にデプロイして、実行して周ります。 恥ずかしいほどに愚直な手法でしたが、YAMLファイルの修正を確実に行うことができました。
修正を施してすべての環境で合致することを確認したら、最後はえいやっ!
git grep -l 'Global\.' | xargs sed -i '' -e 's/Global\./Rails\.configuration\.x\./g’
このRakeタスクでの検証・修正作業のおかげで、コンフィグ移行ミスによる障害を起こすことなく、対応を完了することができました!
Kubernetes上で動かす
さて、コンテナ化ができたら次はそれをKubernetes上で動かすようにします。やることは以下の3点。
- マニフェストを書く
- ツールを使ってマニフェストを管理する
- CI/CDからデプロイする
1. マニフェストを書く
今回使うKubernetesのリソース一覧はこちら。- Namespace
- Deployment
- Service
- ConfigMap
- Secret
- HorizontalPodAutoscaler
- Job
一部の設定値は記事用の適当なものになっているので、ご了承ください。
Namespace
これは至極単純。クラスター内に名前空間を作るためのリソースです。
apiVersion: v1
kind: Namespace
metadata:
name: develop
Deployment
PodやReplicaSetを管理するためのリソースです。RailsとNginxの2つのコンテナで1つのPodが構成されています。
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
selector:
matchLabels:
app: app
template:
metadata:
labels:
app: app
spec:
containers:
- name: app-rails
image: app-rails
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 50m
memory: 400Mi
lifecycle:
preStop:
exec:
command: ["rc-service", "unicorn-app", "stop"] # Graceful shutdown
envFrom:
- configMapRef:
name: app-config
- secretRef:
name: app-secret
ports:
- containerPort: 3000
volumeMounts:
- name: app-assets
mountPath: /app/public
- name: app-sock
mountPath: /app/tmp/sockets
- name: app-nginx
image: app-nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 50m
memory: 100Mi
readinessProbe:
httpGet:
path: /heartbeat
port: 80
initialDelaySeconds: 60
timeoutSeconds: 5
livenessProbe:
httpGet:
path: /heartbeat
port: 80
initialDelaySeconds: 120
timeoutSeconds: 5
lifecycle:
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"] # Graceful shutdown
envFrom:
- configMapRef:
name: app-config
ports:
- containerPort: 80
volumeMounts:
- name: app-assets
mountPath: /app/public
readOnly: true
- name: app-sock
mountPath: /app/tmp/sockets
restartPolicy: Always
terminationGracePeriodSeconds: 35 # Unicorn/SidekiqのTimeoutが30なので少し長く設定
volumes:
- name: app-assets
emptyDir: {}
- name: app-sock
emptyDir: {}
- Resources
- Lifecycle
- ReadinessProbe/LivenessProbe
Resources
設定できる項目はこちら。- Requests
- デプロイするのに最低限必要なリソース量を指定できる
- Worker Nodeのリソース使用量を見ないでデプロイしようとする
- Cluster AutoScalerのNode数やサイズと想定を合わせておかないと、デプロイしてもリソース足りなくてずっとPendingみたいなことが起きてしまう
- Limits
- アプリが使用可能なリソース量を指定できる
- 上限を超えるとコンテナのプロセスがKillされて再起動
Lifecycle
設定できる項目はこちら。- PostStart
- コンテナが作成された直後に実行される
- ただし、フックがコンテナのENTRYPOINTの前に実行されるという保証はない
- 失敗した場合はコンテナを終了させて、restartPolicyに従い再起動させる
- PreStop
- コンテナが終了する直前に呼び出される
- コンテナがすでに終了状態または完了状態にある場合、呼び出しは失敗する
「ユーザーのリクエストを処理中にPodを終了しちゃう」といった無邪気な事故を起こさないためにも、ここの設定はしっかり入れておく必要があります。 Podの終了処理についてはKubernetes: 詳解 Pods の終了の記事が参考になりました。
ReadinessProbe/LivenessProbe
Probeには、- LivenessProbe
- コンテナが動いているか
- 失敗するとKubeletはコンテナをRestartさせる
- ReadinessProbe
- コンテナがServiceのリクエストを受けられるか
- 失敗するとServiceからそのPodのIPアドレスが削除される
LivenessProbeのほうは、いわゆる死活監視なので特筆することはないです。
今回ポイントになるのはReadinessProbeのほう。
「PodがRunning状態 = トラフィックが受けられる状態」とは限らないため、設定しておかないと「Unicornが起動しきってないのにトラフィックを受け始めちゃう」みたいなことが起きるので要注意です。
Service
Podへの接続を解決してくれる抽象的なリソースです。Serviceを介して通信するPodは、Selectorによって決定されます。 (Kubernetesを触り始めた初期、Serviceがピンとこず迷走した記憶があります…)
apiVersion: v1
kind: Service
metadata:
name: app-np
spec:
type: NodePort
selector:
app: app
ports:
- nodePort: 30000
port: 80
ConfigMap
アプリケーションの設定情報を扱うリソースです。分かりやすいので、これは特筆すること無しですね。
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
DB_NAME: "hoge"
...
Secret
クレデンシャルなどの秘密情報を扱うリソースです。base64形式で保存されます。
apiVersion: v1
kind: Secret
metadata:
name: app-secret
type: Opaque
data:
SECRET_KEY_BASE: "ZnVnYQ=="
...
HorizontalPodAutoscaler
DeploymentのReplica数を制御するためのリソースです。その名の通り、CPUなどのメトリクスに応じて自動的にPodを水平分散してくれます。
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app
minReplicas: 1
maxReplicas: 2
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 40
Job
Podが正常に完了したことを追跡するためのリソースで、1つ以上のPodを作成して、指定された数が正常に終了することを保証してくれます。指定された数が正常に終了するとJobが完了状態となり、Jobを削除するとそのJobによって作成されたPodも削除されます。
apiVersion: batch/v1
kind: Job
metadata:
name: app-migrator
spec:
backoffLimit: 1 # リトライ回数
parallelism: 1 # 並列数
completions: 1 # 完了数
template:
metadata:
labels:
app: migrator
spec:
containers:
- name: app-migrator
image: app-rails
envFrom:
- configMapRef:
name: app-config
- secretRef:
name: app-secret
restartPolicy: Never # 失敗時にコンテナを再起動しない
実行するスクリプトは、Kubernetes の Job でマイグレーションを実行するの記事で紹介されているものを参考にさせて頂きました! Kubernetesでのマイグレーションって、結局どの方法が一番いいんでしょうねぇ。
テスト
マニフェストファイルが書けたところで、実際にkubectl applyでマニフェストを適用して動作検証をします。ここで検証しておけば、CIからデプロイしたら「ずっとPodがCrashLoopBackOffなんだけど?」という悲しい思いをしないで済みます。(多分) ローカルでマニフェストファイルの検証を行うときは、Minikubeが便利でした。
ローカルのDockerイメージを使うように設定出来て、Amazon ECRなどのリポジトリにプッシュしなくて済むので、作業がだいぶ楽になります。 やり方はminikubeでローカルのdocker imageを使うの記事がまとめてくれているので、そちらを参考にしてみてください。
2. ツールを使ってマニフェストを管理する
今回はKustomizeというツールを使って、環境ごとのマニフェストを管理・生成できるようにしました。KustomizeはKubernetesのマニフェストをパッケージングできるツールで、Kubectl v1.14.0にて統合されています。 基盤となるベース構成に各環境ごとのカスタマイズを加えてパッケージングが可能で、出力される単一のYAMLファイルをどのようにKubernatesに適用するかは使う側の自由です。
Overlayという機能を使うことで、ベースとなるマニフェストに対してパッチを当てることができるので、
- 各環境で共通となる設定はベースにする
- 各環境で異なる設定のみパッチを当てる
また、ConfigMapやSecretにハッシュ値を付与してバージョン管理することができるので、ロールバックに対応させることも可能です。 Overlayというのがどういう機能かと言うと、
- k8s
- base
- deployment.yaml
- kustomization.yaml
- develop
- deployment_conf.yaml
- kustomization.yaml
- production
- deployment_conf.yaml
- kustomization.yaml
# k8s/base/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: base-namespace
commonLabels:
app: base-label
configMapGenerator:
- name: app-config
secretGenerator:
- name: app-secret
resources:
- deployment.yaml
# k8s/base/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
selector:
matchLabels:
app: app
template:
metadata:
labels:
app: app
spec:
containers:
- name: app-rails
image: app-rails
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 50m
memory: 400Mi
...
kustomization.yamlとdeployment.yamlを用意します。そして次に環境特有の設定を、
# k8s/production/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
bases:
- ../base
namespace: production
commonLabels:
app: production
patchesStrategicMerge:
- deployment_conf.yaml
# k8s/production/deployment_conf.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
spec:
containers:
- name: app-rails
resources: # 本番環境用のResourcesの設定値を当てる
requests:
cpu: 1000m
memory: 3500Mi
こうすることで、ベースとなるDeploymentのマニフェストに対して、Resourcesの値だけを環境特有の値に更新することができるようになります。 環境ごとに丸々
deployment.yamlを書くよりは、だいぶスッキリしますね。
実際にデプロイするときには、
# マニフェストが想定通りになっているか確認
kubectl kustomize k8s/production
# 本番環境用のマニフェストをレンダリングして適用
kubectl apply -k k8s/production
その他のマニフェスト管理ツール
Kustomizeの他にもHelmとかCDK for Kubernetesとかツールの選択肢は結構あります。 その中で今回Kustomizeを選定した理由としては、- カスタマイズの自由度が高い
- 学習コストが低い
ただ、実際に対応を終えた後に改めて振り返ると「Kustomizeじゃ厳しいか…」という場面もありました。
このあたりはやってみて分かったことなので、これから見直していきたいなと思っています。
3. CI/CDからデプロイする
さて、あとはデプロイするのみですね。今回のプロダクトではCircleCIを使っているので、その設定の書き方となっていますが、どのツールを使うにしてもやることは大体同じだと思います。 ということで、デプロイするための
config.ymlはこんな具合です。
version: 2.1
...
jobs:
deploy:
executor: deploy_executor # デプロイ用のexecutorを用意
parameters:
current_stage: # デプロイ先の環境を定義
type: enum
enum: ["develop", "production"]
eks_cluster: # デプロイ先のクラスターを定義
default: "develop"
type: enum
enum: ["develop", "production"]
environment: # ECRのリポジトリを指定
RAILS_IMAGE: xxx.dkr.ecr.ap-northeast-1.amazonaws.com/app-rails
NGINX_IMAGE: yyy.dkr.ecr.ap-northeast-1.amazonaws.com/app-nginx
steps:
- run:
name: set secret access key
command: |
echo 'export AWS_ACCESS_KEY_ID="$APP_AWS_ACCESS_KEY_ID"' >> $BASH_ENV
echo 'export AWS_SECRET_ACCESS_KEY="$APP_AWS_SECRET_ACCESS_KEY"' >> $BASH_ENV
- run:
name: setup kubectl
command: |
aws configure set region ap-northeast-1
aws eks update-kubeconfig --name << parameters.eks_cluster >> --region ap-northeast-1
- checkout
- setup_remote_docker:
version: 18.09.3
- run:
name: build image
command: |
docker version
$(aws ecr get-login --no-include-email --region ap-northeast-1)
export DOCKER_BUILDKIT=1
docker build --no-cache --secret id=ssh,src="/home/circleci/.ssh/id_rsa" -t app-rails .
docker build --no-cache -f docker/nginx/Dockerfile -t app-nginx docker/nginx/
- run:
name: push image
command: |
RAILS_IMAGE_NAME=${RAILS_IMAGE}:$(git rev-parse HEAD)
docker tag app-rails ${RAILS_IMAGE_NAME}
docker push ${RAILS_IMAGE_NAME}
NGINX_IMAGE_NAME=${NGINX_IMAGE}:$(git rev-parse HEAD)
docker tag app-nginx ${NGINX_IMAGE_NAME}
docker push ${NGINX_IMAGE_NAME}
- run:
name: create namespace
command: |
kubectl apply -f k8s/<< parameters.current_stage >>/namespace.yaml
- run:
name: migration
command: |
# ここを参考にしてスクリプトを作成
# https://blog.manabusakai.com/2018/04/migration-job-on-kubernetes/
./.circleci/migration.sh << parameters.current_stage >>
- run:
name: deploy
command: |
cd k8s/base
RAILS_IMAGE_NAME=${RAILS_IMAGE}:$(git rev-parse HEAD)
NGINX_IMAGE_NAME=${NGINX_IMAGE}:$(git rev-parse HEAD)
# ビルドしたイメージを使うように置き換え
kustomize edit set image \
"app-rails=${RAILS_IMAGE_NAME}" \
"app-nginx=${NGINX_IMAGE_NAME}"
# マニフェストを生成して適用
cd ..
kubectl kustomize << parameters.current_stage >>
kubectl apply -k << parameters.current_stage >>
- ビルドの準備
- イメージのビルド(ECR)
- イメージのプッシュ(ECR)
- Namespaceの作成(無ければ)
- マイグレーション
- デプロイ
ここでプッシュしたイメージを使用してPodをデプロイするためには
deployment.yamlの、
spec:
template:
spec:
containers:
- name: app-rails
image: app-rails # ← ココ
kustomize edit set imageというコマンドです。これを使うことで、イメージのタグの指定を更新した上でマニフェストを適用することが出来ます。 こいつは便利ですね。
あとは実際にデプロイして動作確認するだけ。 これでようやく、アプリケーションをコンテナ化してKubernetes上で動かすところまでこぎつけることができました!
まとめ
長々と「コンテナ化してKubernetes上で動かす」ための作業について書かせて頂きました。 Kubernetesは学習コストが高いという話をよく聞きます。確かに難しいし、いまだによく分かっていない部分が多いというのが正直なところです。 しかし今後、というか既にKubernetesを触ることはスタンダードだと思うので、本番環境の移行にチャレンジするというのは、良いアクションだったのではないかと感じています。
Kubernetes上で動かせるようにもなったし、次はGitOpsやProgressive Deliveryに挑戦してみようと、プロダクトメンバーたちと目論んでいます! そんな目論みやKubernetes周りのことを、自分とプロダクトメンバーが執筆しているので、気が向いたらそちらの記事もぜひm(_ _)m
本当はまだまだ積もる話があるんだ!
まだまだ移行作業での積もる話は尽きず、- EKS周りの設計・リソース作り
- ログ収集どうするんだ問題
- どうにもDNS周りが安定しない
- ダウンタイム無しでどう本番環境をEC2EKSに載せ替えればいいのか
ぜひ続編を書けたらと思いますので、機会があればまた読んで頂けたら嬉しいです。 それでは、また。