
これは ドリコム Advent Calendar 2018 の17日目です。
16日目は 廣田 洋平 さんによる、 「”DAC”と聞いたら何を思い浮かべますか?」です。
はじめに
はじめまして、ドリコムでエンジニアをやっているイシカワと申します。普段の業務ではモバイルゲームの開発に携わっています。
アドベントカレンダーの参加は今回が2回目。一昨年は3Dプログラミングについてこんな記事を書きました。今年はモバイルグラフィックス分野から個人的に気になったトピックを紹介します。
シーグラフが示す少し先の未来
今年のシーグラフ開催から数ヶ月後、おもむろにプレゼン資料を読み漁っていたところ、「Moving Mobile Graphics」というコースの存在を知りました。コース概要を読むと、どうも3年前に新設されたコースで、主な目的は最先端のモバイルグラフィックスの技術紹介ということ。お題目には、2018年の技術トレンドを反映して「XR」をテーマにした発表が並んでいます。
そんな中、Unity Technologies による「Maximizing Rendering Efficiency」という発表に目が留まりました。内容は、モバイルのレンダリングパフォーマンス向上のために行った活動の成果報告。Scriptable Render Pipelineの解説の中で、発表者からこんな問題提起がありました。
「従来のディファードレンダリングはなぜモバイルと相性が悪いのか?」
ディファードレンダリングは、PC・コンソールでは一般的に採用されているレンダリング技法の一つ。CGに関心のあるプログラマーにとって、なかなか興味深いテーマです。
ディファードレンダリングとは?
話を進める前に、まず前提知識について簡単に確認します。
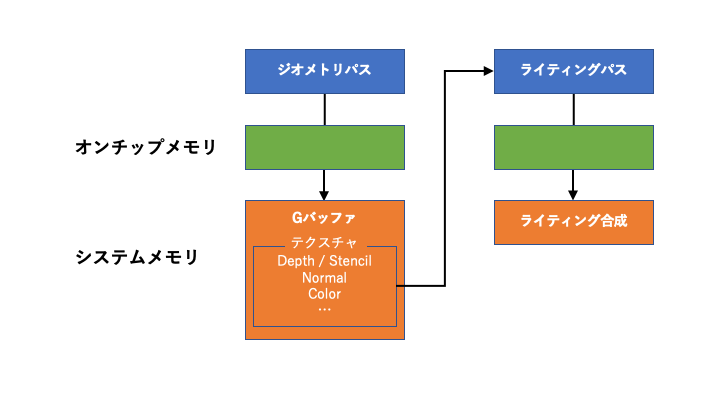
ディファードレンダリングとは、「シェーディングに必要な情報が全て揃うまでライティング計算を遅らせる手法」のことです。この手法では、シーンのレンダリングを「ジオメトリパス」と「ライティングパス」の2パスに分けて行います。これにより、ジオメトリ描画とライティング計算の複雑さを分離できます。
- ジオメトリパス
全てのジオメトリとマテリアルの情報を「Gバッファ」としてテクスチャに出力する - ライティングパス
テクスチャからGバッファを取得して、ライティングを計算し結果と合成する
具体的には、フォワードレンダリング(全て1パスで実行)だと、ライティングの計算量が最悪で O( ジオメトリ数 x 光源数 ) かかってしまう場面で、ディファードレンダリングだと、 O( 光源数 ) で済みます。ディファードレンダリングのライティングパスは、シーンの内容に関わらず、フラグメント(ピクセル)処理をライト形状だけに絞ることができるからです。そのため、ディファードレンダリングは多数の光源を扱う場合に適しています。
より分かりやすい解説を求める方は、次の資料を一読されることをおすすめします。
– 「なぜなにリアルタイムレンダリング」
(補足)
ここでいうディファードレンダリングは、厳密には「ディファードシェーディング」を指します。ただし、説明の都合上、「Maximizing Rendering Efficiency」と言葉を合わせることにしました。
なぜモバイルGPUと相性が悪い?
上の図から分かるとおり、ディファードレンダリングは、オンチップメモリとメインメモリの間でデータ転送の往復が起きるシーケンスになっています。最初のジオメトリパスでは、Gバッファをテクスチャに描画した後、後続のレンダーパスを実行するため、データをオンチップメモリからメインメモリに退避する。次のライティングパスでは、テクスチャからGバッファをサンプリングするため、メインメモリに退避したデータを再びオンチップメモリにロードする。このように、レイテンシの異なるメモリ間で繰り返しデータ転送を行うため、ディファードレンダリングはメモリ帯域幅を浪費しやすい。
一方で、メモリアクセスは電力消費の主要な原因の一つ。本来、モバイルデバイスは、オーバーヒートを回避するため、メモリ帯域幅を制限するなど、性能と電力消費のバランスを優先した設計になっています。電力消費によって発熱が続くと、デバイスを冷却するため、システムはCPU/GPUの稼働率を抑えようとします。つまるところ、従来のディファードレンダリングがモバイルと相性が悪いのは、Gバッファに対するメモリアクセスが非効率で、電力消費を押し上げる原因となるからです。このため、メモリアクセスを最小限に抑えることが、モバイルGPUでディファードレンダリングを実現する鍵となります。
そこで考案されたのが、モバイルGPUのアーキテクチャ特性を活かすアイデアです。
「タイル」を読み書きする
一般的なモバイルGPUは、「Tile Based Deferred Rendering(以下、TBDR)」と呼ばれるアーキテクチャを採用しています。TBDRは、「タイルベース」という名が示すように、スクリーンを複数のタイルに分割して描画する方法が特徴で、これによりレンダリング時に必要なメモリを最小限に抑えることを実現しています。もう一つのキーワード「ディファード」は、オーバードローを回避するため、フラグメント処理をできるだけ遅延させるパイプライン設計が由来になっています。このような設計の都合上、TBDRでは、出力するフラグメントが確定するまで、シェーディングに必要な情報をタイル単位でオンチップメモリに記録します。GPUベンダーによっては、このメモリ領域を「タイルメモリ」や「タイルローカルストレージ」と呼んだりします。
さて、仮にこのタイルメモリに対して、シェーダーから自由にデータを読み書きできると何がおきるでしょうか?ジオメトリパスで出力したデータを、ライティングパスにそのまま入力として引き渡すことができれば、非常にアクセス効率が良くなります。基本的に、Gバッファはフレーム毎に使い捨てるので、タイルメモリに記録できれば、わざわざテクスチャに描画する必要はありません。結果として、メインメモリへのアクセスを回避してメモリ帯域幅を節約できる、というわけです。
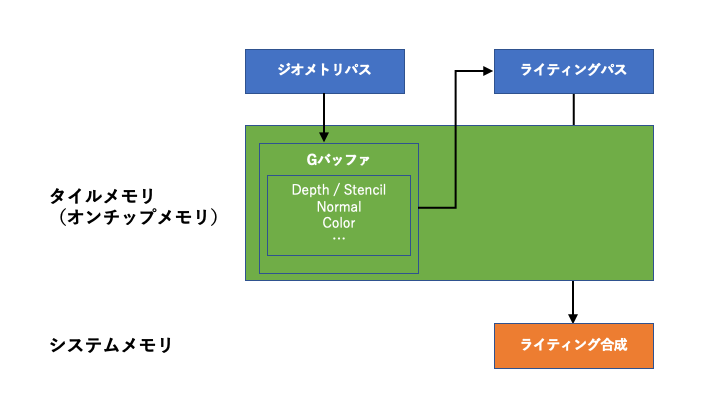
このように、TBDRを前提にした機能ではありますが、主要なグラフィックスAPIは、そろってタイルメモリにアクセスするインターフェースを提供しています。Metal/GLESは、その生い立ちからモバイルに特化するは当然として、最も後発であるVulkanがすでに対応していることに少し驚きを覚えます。
- Vulkan: VkRenderPass, Transient Buffers
- Metal: FrameBuffer Fetch / Image Blocks
- GLES: FrameBuffer Fetch / Pixel Local Storage
では、APIを利用する立場のゲームエンジンはどうでしょうか?Unityの開発状況が気になります。彼らの報告によれば、すでにSRPにおいてVulkanのコンセプトを基に実装を進めているとのこと。しかし、まだ実験段階ですのでリリース時期は未定。プロダクトで利用可能になるのは、もう少し先のお話でしょう。辛抱強く待つことにします・・・
GPUベンダーが遺したGLES拡張
ここに至って自分は無性にコードが書きたくなってきました。Unityの事情に関わらず、今そこにある技術を触ってみたくなったからです。あいにく自分が扱えるのは、iOSで非推奨になったOpenGLだけですが、実際に手を動かすと更に理解が深まるというもの。今回はGLESで頑張ることに決めました。
GLESで利用できるタイルメモリ向けの拡張は次の2つ。
あらためて調べると、ここで挙げた拡張は「OpenGL Extension Registry」への登録時期が意外と古く、今から5〜6年も前までさかのぼります。例えば「EXT_shader_pixel_local_storage(以下、PLS)」は、当時、ARMがImagination Technologiesと協同で開発を主導していた機能拡張。過去のプレゼン資料や記事を読むと、すでにディファードレンダリングへの応用例が紹介されているではないですか。幾つかデモ動画やスクリーンショットを見つけることができます。どうやらディファードレンダリングは、GPUベンダーがモバイル市場でしのぎを削るなか、自社製品を宣伝するためのショーケース的な技術として利用されていたようです。おそらくですが、プラットフォーム独立なVulkanが登場したおかげで、再びその手法に注目が集まっている状況なのでしょう。そのような背景があり、PLSはMaliとPowerVRでサポートする製品が存在する一方、Adrenoなど他のGPUにおけるサポート状況はよく分からないのが現状です。少なくとも自分が調べた範囲では。
今回は幸い、会社の開発端末を探したら、たまたま Mali-G71 を載せた「Galaxy S8」を発見できたので、PLSを試すことにしました。
「EXT_shader_pixel_local_storage」を試す
いざ動くデモを作ろうとすると、1からスクラッチしては時間がかかるので、取っかかりとして、Intelが公開しているAndroidのサンプルアプリを利用しました。マルチレンダーターゲットを使った標準的なディファードレンダリングのサンプルで、OpenGLES 3.0で動作します。また、とてもシンプルなコードで理解しやすく、後から手を加えることも容易な作りになってます。このサンプルを元に、PLSを使ったディファードレンダリングを実装してみました。ソースコードはGitHubに上げています。

PLSを使用するには、まずフラグメントシェーダーの中でPLSに格納する変数を宣言します。今回の場合、GバッファをPLSで宣言すると、インターフェースブロックを用いて以下のような記述になります。
__pixel_local_EXT FragDataLocal
{
layout(rgb10_a2) vec4 albedo;
layout(r11f_g11f_b10f) vec3 normal;
layout(r32f) float depth;
} fragData;
| アルベド | RGB10A2 | 4バイト |
| 法線ベクトル | R11G11B10 | 4バイト |
| 深度 | R32 | 4バイト |
変数のデータ型は、layout修飾子を使って指定します。PLSのデータサイズは、1フラグメントあたり最大で16バイトまで。Gバッファの種類が増えると場合によっては、狭いスペースにデータを圧縮して詰め込む必要が出てきそうです。
以上で、シェーダーから変数を参照してタイルメモリにフラグメント単位で読み書きできます。
fragData.albedo = vec4(albedo, 1.0); fragData.normal = normal; fragData.depth = gl_FragCoord.z; ... vec3 albedo = fragData.albedo.rgb; vec3 normal = fragData.normal; float depth = fragData.depth;
ちなみに、PLSの変数スコープですが、レンダリングが完了するとGPUによって自動的に破棄されます。したがって、アプリケーションで明示的に解放する操作は不要です。そもそもレンダーバッファを別に確保する必要がないので、テクスチャに描画する場合とは違い、CPU側で煩雑なバッファ操作が発生しません。そのため、アプリケーション全体としてソースコードが簡潔になるという、うれしい副次効果があります。
さて、アプリケーションを実行してGPUのメモリ使用量を計測したところ、こんな結果になりました。以下は、dumpsys meminfo で出力したレポートです。ひと目で GL mtrack が減ったことが分かります。
# 変更前 Pss Private Private SwapPss Total Dirty Clean Dirty ------ ------ ------ ------ Native Heap 24844 24800 16 278 ... (省略) EGL mtrack 99984 99984 0 0 GL mtrack 214331 214331 0 0 Unknown 373 372 0 91 TOTAL 371411 343615 21432 1030
# 変更後 Pss Private Private SwapPss Total Dirty Clean Dirty ------ ------ ------ ------ Native Heap 21717 21668 28 503 ... (省略) EGL mtrack 99984 99984 0 0 GL mtrack 162723 162723 0 0 Unknown 418 408 8 180 TOTAL 324293 289471 24100 2023
元のGバッファのサイズを見積もると、「Galaxy S8」のスクリーンサイズは 1440×2960 なので
(14402960)(4*3) = 51148800バイト ≒ 51.1MB
メモリ使用量の差が見積もりとほぼ一致します。レンダリングの挙動を変えずに、見事に使用メモリを削減できました。
一方で、フレームレートは、元のサンプルが60FPSで動作していたので、目立った差を確認できませんでした。最近のモバイルDDRは帯域幅が大きいからでしょうか。例えば、「Galaxy S8」に載っているLPDDR4の場合、25.6GB/秒で、ノートPC並の帯域幅をもっています。60FPSだと426MB/フレームとなる計算で、今回のケースだとかなり余裕があります。反対に、少し古めの端末だと帯域幅の不足がボトルネックとして現れるかもしれません。
まとめ
モバイルGPUでディファードレンダリングを最適化する方法を解説しました。もっと詳しい情報を知りたい方は、ぜひ参考資料を読んでみてください。
一般的にモバイルGPUはTBDRと呼ばれるアーキテクチャを採用していて、スクリーンを小さいタイルに分割し描画します。ディファードレンダリングでは、GPUのタイルメモリをGバッファの読み書きに利用すると、システムメモリへのアクセスを回避してメモリ帯域幅を節約できます。
現世代のAPIであるMetal/Vulkanは、タイルメモリにアクセスする機能を標準でサポートします。一方、旧世代のGLESは、特定のGPUベンダーが提供する機能拡張が必要になります。この記事では私のスキルセットの事情で、GLESを使った実装例を紹介しました。低レベルから理解することは、その上に乗っかっている技術スタックを理解するのに役立ちます。ただし、これから学ぼうとする人は素直にモダンなAPIを使いましょう!
モバイルGPUはデスクトップGPUと比較してハードウェア上の制約が多いですが、数年前と比較して遥かに状況は改善しています。ハイエンドの世界で枯れた手法が、モバイルで再び注目を集めるのは、そう珍しいことではないでしょう。ディファードレンダリングに限らず、自分たちの表現の幅を広げる可能性があるならば、流行り廃りに関係なく、その技術を追求していきたいものです。
参考資料
- 「GPU Pro 5 – Deferred Rendering Techniques on Mobile Devices」
- 「GPU Pro 7 – Physically Based Deferred Shading on Mobile」
- 「OpenGL Insights – Performance Tuning for Tile-Based Architectures」
- 「PowerVR Hardware.Architecture Overview for Developers」
- 「Is there any relation between processor clock speed and heating effects?」
- 「Pixel Local Storage on ARM Mali GPUs」
- 「Efficient Rendering with Tile Local Storage」
- 「ARM MaliTM GPU OpenGL ES 3.x Developer Guide」
- 「Dwarf Hall: physically based rendering on a PowerVR GPU」
- 「PowerVR Supported Extensions OpenGL ES and EGL」
ドリコム Advent Calendar 2018、明日は 村松健太 さんの記事です。