
これはドリコム Advent Calendar 2016 2日目です。
自己紹介
こんにちはインフラストラクチャー部のひらしーです。
日々ドリコムのインフラ自動化やInfrastructure as Code、群馬県の誤解を解くことに勤しんでいます。
また、最近は自分で作ったツールでツールのデプロイをするのがマイブームです。
オートスケーリングについて
アクセス数予測の難しいインターネットサービスを運用する際に、個々の処理単位(仮想マシン等)を自動で増減できると、インフラエンジニアが他のサービス信頼性向上に割ける時間の向上や適正なサーバ数によるコストの削減が見込めます。
2016年12月現在IaaS各社サービスの仮想マシン単位のオートスケール対応について比較してみます。
※各社管理画面上の設定のみで完結するオートスケーリングシステムがある場合のみ○にしています
| Iaasサービス | オートスケール対応 | スケールする際の指標 |
|---|---|---|
| Amazon Web Service(AWS) | ○ | Amazon CloudWatchで取得できる指標 |
| Google Cloud Platform (GCP) | ○ | Stackdriver Monitoringで取得できる指標 |
| Microsoft Azure | ○ | CPU,Azureキューストレージの値 |
| IBM Bluemix | ○ | CPU,メモリー,JVMヒープ |
| IDCF Cloud | ☓ | – |
| さくらのクラウド | ☓ | – |
| NIFTY Cloud | ○ | CPU,メモリ,ネットワーク帯域 |
| GMOクラウド | ○ | CPU,メモリ,ディスク |
| IIJ GIO | ☓ | – |
上記のように各社でのオートスケール対応状況及び仕様はバラバラとなっており、
- オートスケール未対応のIaaSに他のメリットがあり採用したが、対応したい場合
- 特定サービスに必要な条件でのスケールがIaaSの機能で実現できない場合(高度なアルゴリズムを利用したオートスケーリングシステム等)
- 複数のIaaSを使用していて共通のオートスケールの仕組みを採用したい場合
このようなケースでは独立した監視システムやミドルウェアでオートスケーリングシステムを構築することが有効になるでしょう。
本記事は弊社にて実際に本番環境導入予定のZabbixを利用したオートスケーリングシステムを構築した際のまとめです。
Zabbixとオートスケーリングシステムの親和性
監視システムを利用したオートスケーリングシステムにてスケール条件となる異常検知として用いる場合に以下の要件が求められます。
- 必須要件
- 特定サーバが属すグループの集計関数の結果をトリガーとできる(リクエストを捌くサーバのCPU負荷の単位時間平均値等)
- 監視システムからIaaSに以下の命令がトリガーの契機で実行できること(コマンド・スクリプトが実行できればOK)
- スケールアウト/イン(仮想サーバインスタンスの契約/解約)
- サービスアタッチ/デタッチ(ロードバランサー,ファイアウォール,プロキシ等)
- API又はCLIによる監視対象の状態変更
- あると利便性・精度が高くなる要件
- 精度の高い監視データ管理(AWSのオートスケーリングシステムのメトリクス取得間隔は有料でないと5分間隔と要件次第では精度が足りない場合も)
- メトリクスのグラフ表示
最近採用されているメジャーな監視ミドルウェアでは以下のような対応状況になると思います。
| 監視ミドルウェア | 集計関数 | トリガー実行 | API/CLI | 精度(最短) | グラフ | 備考 |
|---|---|---|---|---|---|---|
| Zabbix | ○ | ○ | API | 秒単位 | 充実 | 設定に癖あり |
| Munin | △(プラグインで拡張) | ○ | API/CLI | 秒単位 | 充実 | |
| Nagios | △(プラグインで拡張) | ○ | CLI | 秒単位 | △(プラグイン) | |
| Sensu | △(プラグインで拡張) | ○ | CLI | 秒単位 | △(プラグイン) | 設定ファイルがJSON |
Zabbixは設定に癖があるもののデフォルトで監視単位の集合関数をサポートしており、オートスケーリングシステムを構成しやすいと言えるでしょう。
IaaSのAPI
最近のIaaSはほとんどAPIに対応していますが、オートスケーリングシステムを適用するには以下の点に注意が必要です。
- IaaS側実行中進捗状況の取得
API実行の成功・失敗、又は長時間掛かった場合にリトライや通知をするために必要となります。
進捗状況が取得出来ない場合は一定時間経過をタイムアウトとみなし、状況によっては冪等性担保のため中途半端に作成してしまったサーバの削除等余計な処理をする必要があり、オートスケーリングシステムとして作るのは若干困難となるかもしれません。 - オートスケーリングシステムで管理する情報
AWSやCloudstackを採用しているIaaSにはリソースタグやユーザーデータという、IaaS基盤側で仮想マシンインスタンス毎に情報を管理してくれる機能があり、オートスケーリングシステムでの状態管理(特に後述するライフサイクルの状態)に利用できます。これを使用しない場合は自前で仮想マシンの状態を管理したデータベースとIaaS側との同期システムが必要となります。 - APIの制限と信頼性
IaaSの仕様によってはAPIの使用回数制限があるので、それを回避するためにオートスケールの間隔を伸ばす対策等を入れる必要があります。
また、IaaS側の障害が発生してもオートスケーリングシステムに影響されない必要があります。とはいえIaaS側の障害時は恐らくスケール条件の取得もスケール自体もできないと思われるので「IaaSの障害が発生し、操作不能になったら何もしない」程度の対応しかできないかもしれません。
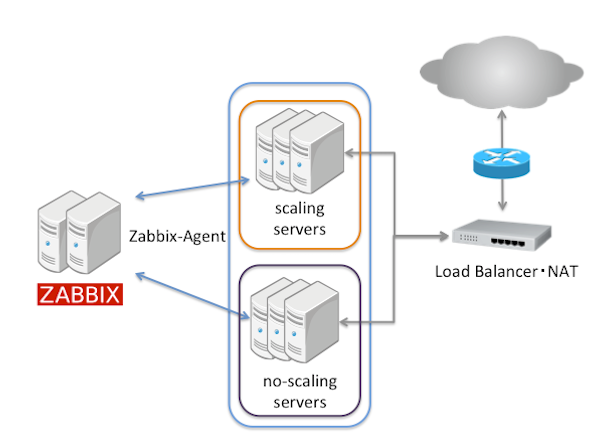
ネットワーク構成
外部のネットワークからのリクエストに対して処理を分散する場合は以下のような構成になります。
ここで重要なのは同等のスケーリングしない仮想マシンを用意することです。
このスケーリングしない仮想マシン数をコントロールすることによりスケールインした時の最低台数でのサービス維持やサービスのメンテナンス終了時のみ台数を増やしたい等アドホックの台数制御が可能となります。
ライフサイクル
オートスケーリングシステムを仮想マシンインスタンス側から見ると契約~サービス稼働~サービス停止~解約のような状態遷移になります。
以下、一例ですがこのようにライフサイクルを設計しておくことがオートスケーリングシステムを実現するための肝になります。
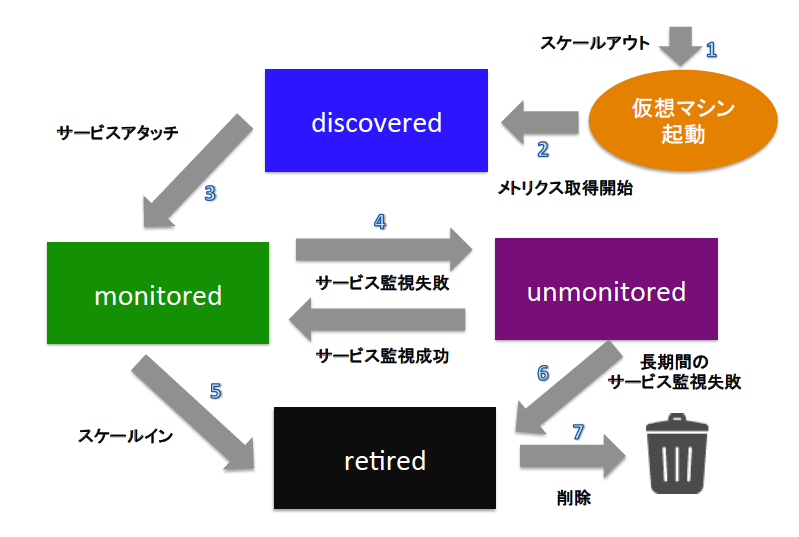
- discovered
スケールアウトにて作られた仮想マシンが監視システムに登録された状態 - monitored
監視システムのサービス監視が成功し、サービス稼動状態となった状態(ロードバランサー等に登録された状態) - unmonitored
サービス監視に失敗に一時的にサービスから除外された状態 - retired
スケールイン・監視失敗により退役となり、解約を待つ状態
ライフサイクルのZabbix実装例
- Zabbix3.0.3を利用した上での説明です。
- 各章の先頭の番号は上記ライフサイクル中の矢印の数字と一致します
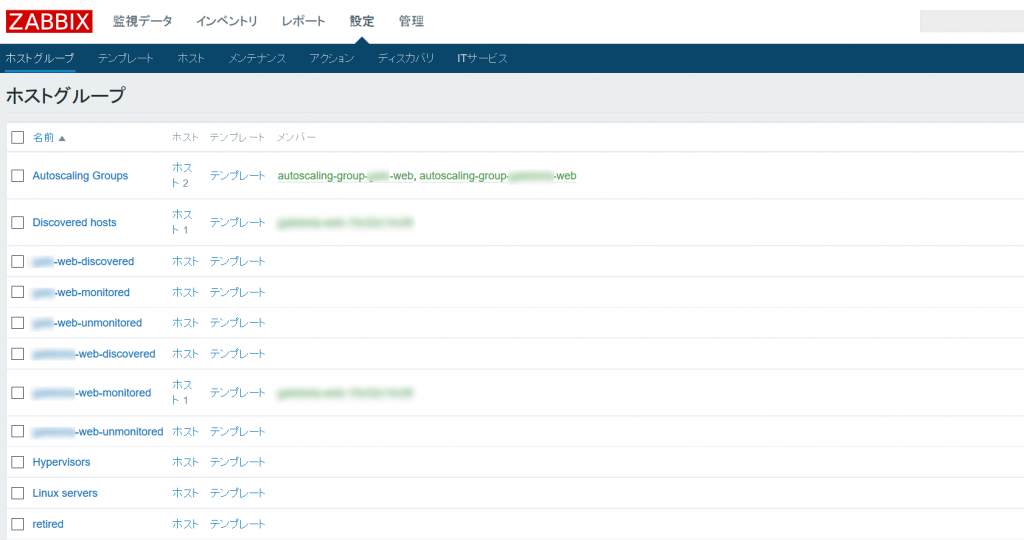
ライフサイクルとホストグループ
仮想マシンインスタンスがライフサイクルのどの状態に位置するのかをZabbix上で表現するにはホストグループを利用するのが良さそうです。
以下はスケーリンググループとライフサイクルの状態名をハイフンで繋いだ文字列にしています。
1. メトリクス取得
Zabbixでの仮想マシンインスタンスの登録はネットワークディスカバリ、ローレベルディスカバリ、監視対象の自動登録があります。オートスケーリングシステムのような動的に監視対象が変化するものは自動登録が適しているでしょう。
また、仮想マシンを自動登録させるには以下が必要となります。
- Zabbixエージェントのインストール
IaaSであれば既にインストール済み仮想マシンからのサーバクローンで問題ないでしょう - メトリクス収集先Zabbixサーバのアドレス(ServerActive設定)
- 仮想マシン識別情報(HostMetadata,HostMetadataItem)
Zabbixサーバから各仮想マシンを識別する情報です。
デフォルト設定のホスト名がそのまま監視対象名になる場合は問題ないですが、別名を付ける場合は各仮想マシンのzabbix_agentd.confのHostMetadata又はHostMetadataItemを起動時に変更する仕組みが必要になります。 - 監視対象登録後に適用されるテンプレート
仮想マシンが監視対象となった際にオートスケールのために必要なメトリクスが適用されるためのテンプレートを用意します。
テンプレートには監視システムがオートスケールの条件に利用するため以下の情報が収集できるようにします。- CPU使用率
- サービス死活監視ステータス
2. サービスアタッチ
テンプレートに登録したCPU使用率・死活監視ステータスといったアイテムを利用したトリガーと実際にオートスケールを実行するタイミングを定義するアクションによって実現します。
アクションではコマンドを直接実行するリモートコマンドと独自のメディアを定義しメッセージ送信する方法の2つがあります。
一見リモートコマンドのほうがお手軽にコマンドを実行できるので選択しがちですがZabbixの場合だとリモートコマンド実行時は渡せる引数に利用できるZabbix変数に制限があるので注意が必要です。個人的にはコマンドを使う場合でもメディアにカスタムアラートスクリプトを定義して利用したほうが変数が利用できない罠に嵌まらずに済むケースが多いと思います。
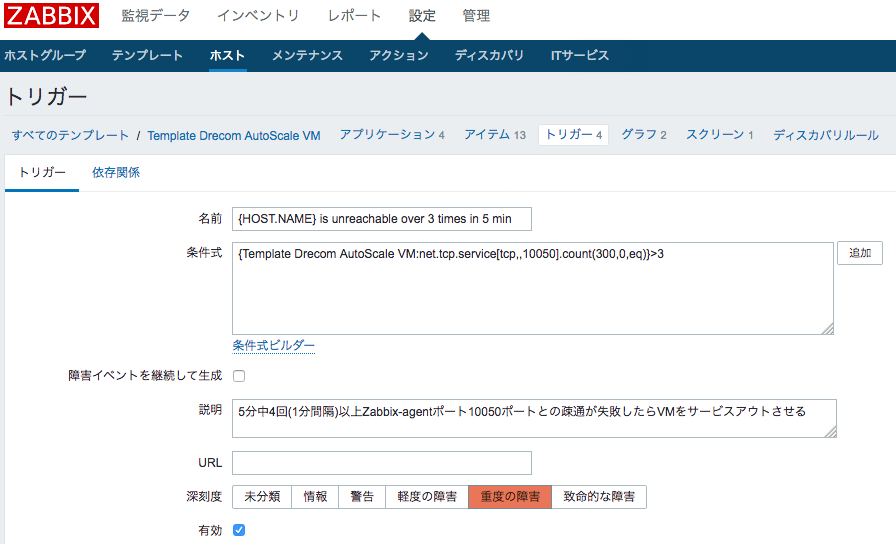
3,4. サービス監視
サービスアタッチにより稼動状態となった仮想マシンを監視し、監視失敗時にサービスからの切り離しや使用不能とみなし退役をさせる必要があります。
こちらもオートスケーリング用テンプレートに「N秒サービス監視が失敗したらサービスから切り離すスクリプトを実行」「さらにN秒サービス監視が失敗したら仮想マシンを解約するスクリプトを実行」のように設定します。
設定例
0,5. スケールアウト・イン
Zabbix上にIPアドレス127.0.0.1の仮想のホストを作成し、そのホストにて各仮想マシンインスタンスの集合関数のアイテムとトリガーを定義します。
スケールする条件としてはサービス要件によって異なってくるとは思いますが弊社では以下のようなスケール条件にする予定です。
- 検証メトリクス: 100%- CPU idle
- 評価値: 監視対象仮想マシンインスタンスの上記メトリクスの平均値
- トリガー監視間隔: 1分
- トリガー発動間隔: 3分内で2回以下の条件を満たした時発動
| 種別 | 条件 | アクション |
|---|---|---|
| スケールアウト | 40%を越えた時 | 全体の2割を切り上げた数を追加 |
| スケールアウト | 90%を越えた時 | 全体の8割を切り上げた数を追加 |
| スケールイン | 20%に満たさない時 | 全体の2割を切り上げた数を削減 |
6. 仮想マシンインスタンス削除
スケールインや監視失敗によって不要となった仮想マシンはサービスから切り離します。
この際に解約まで一定時間余裕を与えると、監視失敗時の原因究明や解約時の連携システムの情報同期がやり易くなるでしょう。
さいごに
本記事ではオートスケーリングシステムに絞って記載してきましたが、実際にはスケールアウトした仮想マシンインスタンスが自動でサービスへの役割を果たすためのプロビジョニング・デプロイの仕組みが必要となります。
弊社での以下の取り組みも参考になればと思います。